Lab 4:调度
调度
任何操作系统中,都可能出现进程的个数大于处理器个数的情况,这就需要考虑如何分配处理器资源。一般进程的执行是CPU计算和IO操作的循环,当进程长时间等待某种资源时,为了更好地利用CPU资源,应选择其他准备好的进程来代替它;当进程完成所需的时间过长时,为了让其他已经在系统中的进程等待时间不要过长,也需要在某个适当的时间暂停当前的进程, 因此便需要多进程并发,也就需要调度。
调度指的是决定一个进程在什么时候、是否要暂停,从一个等待队列中选择另一个进程来代替它,调度涉及调度策略的选择,也包含完成进程切换的动作。操作系统通过不断地调度,造成并发的效果,同时也为每个进程造成独占资源的假象。调度涉及以下的问题:
- 如何进行进程的切换?这是通过上下文的切换来实现的。上下文是一个进程运行状态的描述,包括程序计数器(
%eip), 栈底指针(%ebp), 以及其他一些寄存器的值。在进程切换时,首先要保存旧进程的上下文在内核栈上,选择一个新进程,从该进程的内核栈上加载它的上下文,然后CPU就开始执行新进程%eip指向的指令。上下文的保存和加载使得程序可以从上次调度被暂停的地方接着进行,对进程来说,就好像切换从来没有发生过一样。 - 如果进程不是调用
sleep主动放弃CPU,如何让进程的切换透明化呢? xv6简单地使用时钟中断来完成。当时钟中断到来时,进程陷入中断处理程序,在内核中调用yield来进行上下文切换。 - 多个CPU同时在切换进程时,由于需要对进程表进行修改,可能会产生竞态条件,因此还要用锁来避免竞争。
- 进程结束时,需要释放资源。进程不能自己释放自己的所有资源,因此内核中还必须有一个角色负责监测进程的结束、释放资源。
- 当进程调用
sleep进入睡眠时,调度也会发生。这时,要确保有其他进程可以唤起该进程,因此xv6需要提供一套进程间通信的机制,例如sleep和wake up。
本次实验将详细研究整个调度的过程,看xv6如何解决上述问题,并实现优先级调度算法。
在开始实验之前,需要了解以下事实: xv6永远不会从一个用户态进程切换到另一个用户态进程。在xv6中,调度发生在以下几种情况:1. 进程调用sleep进入休眠,主动放弃CPU,这会导致进程进入内核态,保存进程的上下文并加载调度器的上下文,当调度器返回时,该进程仍处于内核态;2. 进程收到时钟中断,已经运行完一个时间片,这也会导致进程进入内核态,并在yield中将控制权交给调度器;3. 进程调用exit结束。 在这些情况下,切换的过程都是 陷入内核→保存上下文→切换到调度器的上下文 → 切换到新进程的上下文(在内核态中) → 返回新进程的用户态。
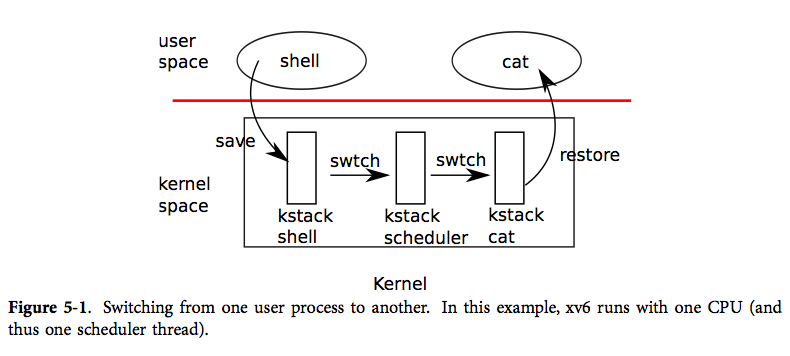
TODO1: 阅读proc.c中的函数
我们先看调度发生的一般场景:进程运行完时间片,被迫放弃CPU,选择下一个进程调度。
xv6的时钟每100毫秒就产生一个中断,以此实现进程时间分片。时钟中断是由lapic产生的,因此每个cpu可以独立地接收它的时钟中断。当接收到时钟中断时,进程会开启保护模式,陷入到内核态,来到中断处理程序的入口,然后在alltraps中保存中断帧,调用traps,traps根据中断号来判断应该执行哪种程序。在traps的最后,有可能调用yield使进程放弃CPU:
1 | |
yield
yield函数在proc.c中实现:
1 | |
yield是将目前进程的状态从RUNNING改为RUNNABLE,让进程进入等待队列,然后调用sched将控制权转移给调度器。由于进程PCB存放在进程表上,因此对状态进行修改之前要首先acquire(&ptable.lock)获取进程表的锁,等进程再次被调度时,它会返回到yield中sched的下一行,释放进程表锁。这里要注意,在上一个实验中,我们知道xv6的内核中临界节内不允许中断,所以在进入sched之前,中断是已经关闭的状态。
sched
sched的任务是首先确保进程有放弃CPU,进行调度的条件,然后调用swtch进行上下文切换,转到cpu调度器scheduler上。
1 | |
首先,holding(&ptable.lock)判断该cpu是否已经持有了进程表的锁,因为多个CPU在调度过程中都需要访问进程表,假如这个cpu进入调度之前,没有先持有锁,那就有可能使其他cpu也同时进行调度,同时访问进程表,可能会出现两个cpu选择了同一个进程调度的情况。
然后mycpu()->ncli!=1判断该cpu调用pushcli的次数是否恰好为1,否则会报错。在上个实验我们知道,每一次调用acquire获得锁,就会使ncli加一,释放锁后ncli减一。所以ncli为1就说明这里只允许进程持有一个锁,也就是说,进程被切换时,必须持有进程表的锁,并且必须释放其他所有的锁。持有进程表的锁是为了保证CPU的调度是互斥的,防止竞态条件,而释放其他所有锁是为了防止死锁的情况出现。
如果p->state==RUNNING,进程的状态是仍在运行,不可以进入调度。这是操作系统中约定好的分工:sched应该只负责进入调度器,而不应该判断进程是因为什么原因而被暂停的,所以假如进程是终止了,应该由exit来将状态变为ZOMBIE,如果进程是被时钟中断了,应该由yield将状态变为RUNNABLE,休眠也同理。进入sched之前,进程的状态应该已经改变好。
sched最后通过readeflags()FL_IF,检查标志寄存器中IF段的值,确保中断已经关闭,然后它将mycpu()->intena暂时保存起来,这个变量表示CPU在调用yield之前,中断是否被允许,因为之后在调度器中要调用sti开启中断,可能会破坏原来CPU的中断状态,所以暂存起来,等从调度器返回(进程被重新调度)的时候,再恢复这个值。
sched调用swtch(&p->context, mycpu()->scheduler)来切换上下文,swtch的汇编代码如下:
# Context switch
#
# void swtch(struct context **old, struct context *new);
#
# Save the current registers on the stack, creating
# a struct context, and save its address in *old.
# Switch stacks to new and pop previously-saved registers.
.globl swtch
swtch:
movl 4(%esp), %eax
movl 8(%esp), %edx # swtch的第二个参数,即新的上下文
# Save old callee-saved registers
pushl %ebp # 保存旧进程内核栈的栈底指针
pushl %ebx # 保存旧进程%ebx寄存器
pushl %esi # 保存旧进程%esi
pushl %edi # 和%edi寄存器
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp #
# Load new callee-saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
首先,进程上下文中包含的信息有:
1 | |
为什么只需要保存这些呢?假设进程在某个函数中,发生了上下文切换,那么首先不需要保存的是调用者保存的寄存器,如%eax,%ecx,%edx,因为该函数的调用者已经提前把它们保存在进程的栈上了。也不需要保存段寄存器,如%cs等,因为在指令地址发生改变的时候,这些寄存器也会同时改变。所以,要保存的有栈底指针、%ebx、程序计数器%eip、参数寄存器%edi、%esi。
上下文保存在进程内核栈上:
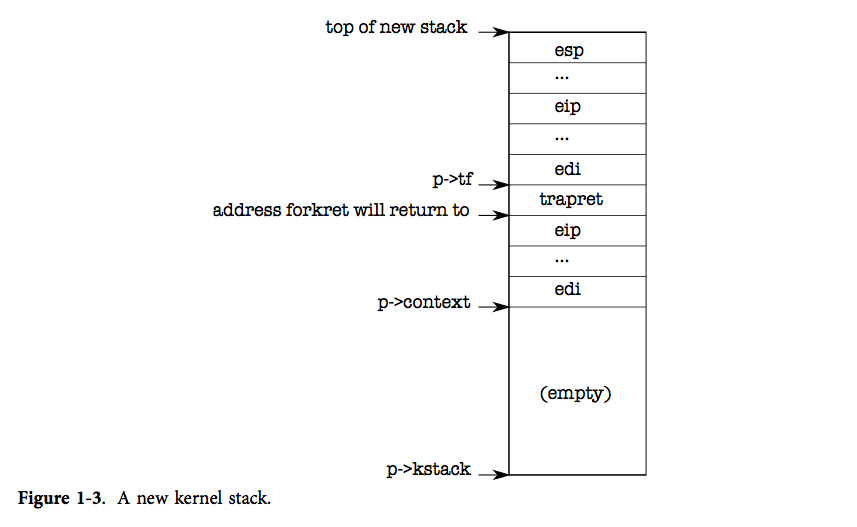
在进程从yield进入到sched再进入到swtch的这个时候,cpu首先是运行在旧进程的内核栈上的。在这里,swtch传入两个参数,第一个是旧进程上下文的指针的地址,第二个是该cpu调度器进程的上下文的指针,调度器的上下文也是调度器上一次调用swtch时保存的。我们逐条指令分析上下文切换的过程:
swtch:
movl 4(%esp), %eax # 第一个参数
movl 8(%esp), %edx # 第二个参数
这两条指令中,%esp指向旧进程内核栈现在的栈底,因为它调用了swtch,所以(%esp)上存放的是sched中swtch的返回地址。4(%esp)和8(%esp)分别是swtch的第一个和第二个参数,也就是旧进程上下文和新进程(调度器)上下文的指针。
画出旧进程内核栈:
| … | |
|---|---|
| 旧进程上下文指针 | p->context |
| 调度器上下文指针 | mycpu()->scheduler |
| %esp→ | mycpu()->intena = intena 对应指令的地址 |
# Save old callee-saved registers
pushl %ebp # 保存旧进程内核栈的栈底指针
pushl %ebx # 保存旧进程%ebx寄存器
pushl %esi # 保存旧进程%esi
pushl %edi # 和%edi寄存器
这四条指令是将旧进程的上下文保存到当前栈(旧进程的内核栈)上。
| … | |
|---|---|
| 旧进程上下文指针 | &p->context |
| 调度器上下文指针 | mycpu()->scheduler |
| mycpu()->intena = intena 对应指令的地址 | |
| ebp | |
| ebx | |
| esi | |
| %esp→ | edi |
# Switch stacks
movl %esp, (%eax) # 令p->context = %esp
movl %edx, %esp
然后交换栈。从第一、二条指令我们知道,现在(%eax)中是旧进程的上下文指针,令(%eax)=%esp,也就是让旧进程上下文指针重新指到现在它保存的地方。而%edx中是调度器上下文指针,把%edx赋给%esp,使栈底指针指向了调度器上下文所在的位置,这样,就从旧进程的内核栈切换到了调度器所在的栈(前者是代表用户进程的,是用户进程在内核态下运行时使用的栈,后者不代表任何用户进程,它是内核进程进行时使用的栈)。
| (旧进程的内核栈) | … |
|---|---|
| 旧进程上下文指针 | &p->context |
| 调度器上下文指针 | mycpu()->scheduler |
| 旧进程中swtch返回地址 | mycpu()->intena = intena 对应指令的地址 |
| ebp | |
| ebx | |
| esi | |
| p->context→ | edi |
| (调度器所在的栈) | … |
|---|---|
| 调度器中swtch返回地址 | ret |
| 调度器的上下文 | ebp |
| ebx | |
| esi | |
| %esp→ | edi |
栈切换之后,栈底指针指向调度器上下文所在的地址。现在,就可以从栈上pop出调度器的上下文了:
# Load new callee-saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
最后,ret会返回到scheduler中,swtch的下一行位置(而不是返回sched)。这样,cpu控制权就从旧的进程转移到了调度器。从swtch指令中,我们没有看到对%eip的显式保存,这是因为旧进程的%eip在用call swtch调用swtch时就已经隐式地保存在了%ebp的前面,同样,ret指令也隐式地把调度器栈上的返回地址加载到了%eip中。
scheduler
scheduler就是上述的调度器。每一个进程最终都会将控制权返回到调度器,调度器会从等待队列中选择一个进程开始运行,它会调用swtch保存自己的上下文,然后切换到该进程的上下文开始运行。
1 | |
调度器是一个两层的for循环。外层循环是无限循环,这意味着调度器永远不会返回。内层循环中,调度器遍历进程表,选择进程运行。在CPU开始的时候,它就会调用scheduler.
scheduler每一次从内层循环退出,进入外层循环,都要显示地执行sti指令允许中断,并且要将ptable锁释放之后再重新获取。这两个步骤都是很有必要的,因为从内层循环退出,意味着调度器可能检查了一遍ptable,没有找到可以运行的进程,这时有可能所有的进程都在等待IO中断,如果不执行sti开启中断的话,IO中断永远也不能到达进程。而如果一个闲置CPU的调度器一直不释放锁,那么其他CPU也不能访问ptable,进行上下文或者系统调用了,所以就没有CPU能够将一个进程的状态改为RUNNABLE,这个CPU也无法跳出循环。
scheduler内层循环遍历进程表,寻找下一个RUNNABLE的进程并切换到进程的上下文中运行。
1 | |
当调度器找到了一个RUNNABLE的进程,就将cpu->proc 设置为它的PCB指针,然后调用switchuvm将该进程的内存空间、页表加载进内存中,并将进程状态设置为RUNNING.
然后,调用swtch进行上下文的切换。现在,第一个参数(旧的上下文)是调度器的上下文指针的地址&(c->scheduler), 第二个参数是新进程上下文的指针。这个swtch将保存调度器的上下文,并将c->scheduler指向保存的位置,然后从调度器的栈换到新进程的内核栈,从栈上加载新进程的上下文,然后转到新进程sched中swtch返回处运行。新进程将马上释放ptable 锁。
有的时候,swtch也不一定是返回到新进程的sched处。如果该新进程是刚刚被fork产生,这是它第一次被调度,那么swtch就会返回到forkret处,在forkret中释放ptable锁,再从forkret返回到trapret,退出内核态。
当调度器从swtch返回,意味着有某个进程调用了sched把控制权返还给它,它首先调用swtchkvm转换到内核的页表,然后将c->proc置为0,表示暂时没有进程在该cpu上运行。然后,如果该进程不是位于ptable的最后一个槽,调度器就会继续查找下一个RUNNABLE的进程,重复以上步骤。否则,它将释放ptable锁,并开启中断。
睡眠与唤醒
睡眠和唤醒提供了进程间通信的机制,它们可以让一个进程暂时休眠,等待某个特定事件的发生,然后当特定事件发生时,另一个进程会唤醒该进程。睡眠与唤醒通常被称为顺序合作或者有条件同步机制。 睡眠是调度发生的另一种情况,当进程调用sleep进入休眠时,它会调用sched把控制权交给调度器。
sleep有两个参数,第一个参数chan是休眠被唤醒的信号,这个信号使得进程可以互相通信,一个进程调用sleep(chan)进入休眠,另一个进程用同样的chan调用wakeup(chan)就可以把它唤醒。第二个参数lk是调用休眠时必须持有的一个锁,这个锁主要是为了防止“遗失的唤醒”问题。一般,进程如果需要休眠,它需要循环判断某个条件是否成立(例如磁盘是否已经准备好),如果还不成立,就会调用sleep进入休眠。例如:
1 | |
之所以需要while循环判断,是因为如果某次事件成立了,进程从休眠中唤醒,但它被唤醒之后可能不是马上就被调度、马上就开始执行后面的代码,所以在这中间,有可能条件又不成立了,所以需要唤醒之后马上继续判断。
而如果没有上面所说的lk锁,就可能发生,while判断条件不成立,进程准备进入休眠;但是这时候发生调度,另一个进程使得条件成立,想要唤醒进程,但这时候因为它还没休眠,所以找不到进程可以唤醒。再切换回原来的进程时,这个进程不知道条件已经成立了,它会进入休眠,并且之后再没有办法唤醒它。 因此,必须确保在条件判断和调用sleep是不会被wakeup打断的,即wakeup不可以在进程真正进入sleep之前被调用。这可以用锁来实现。
1 | |
sleep首先判断是否持有lk锁,否则报错。 然后,sleep需要释放lk锁并获得ptable->lock。这里有两种情况:
lk不是ptable->lock,则因为wakeup函数也要求获得ptable->lock,所以释放lk是没问题的,ptable->lock代替了lk,保证不会出现“遗失的唤醒”问题。必须在释放lk之前,先获取ptable.lock,否则有可能在释放lk之后,获取ptable.lock之前,发生调度,另一个进程此时便可以调用wakeup。而之所以要获取ptable->lock是因为之后要对进程表进行访问、修改,并且要调用sched进入调度器。lk就是ptable->lock,则不需要任何操作。不可以先释放ptable.lock然后再重新获取,原因跟上面lk释放与ptable.lock获取的顺序不能调换的原因是一样的。
然后进程就要进入休眠。
1 | |
调用sched之后,该进程就被暂时挂起了,sched会将上下文切换到调度器,再从调度器切换到另外的进程。当这里的sched返回的时候,表明进程已经被唤醒。它要将等待条件清为0,然后重新获得lk锁。重新获得锁时,则不必先获得lk,再释放ptable.lock,因为此时进程已经从休眠中唤醒了,它不会担心在释放和重新获得之间,其他进程调用wakeup,其他进程是否在这中间调用wakeup对该进程是没有影响的。
对应地,wakup函数从ptable中找到状态为SLEEPING并且在chan上休眠的进程(可能多个),将它的状态设置为RUNNABLE,这样它就可以被CPU的调度器调度。
1 | |
wakeup是wakeup1的加锁版本。wakeup因为要访问并修改ptable,所以需要持有ptable.lock。wakeup作为系统调用让用户去调用时,操作系统而非用户要负责获取ptable.lock锁; 但在系统中,例如exit等函数也会调用wakeup,但在这之前它就已经获得了ptable.lock锁,所以也为内核提供了不加锁的wakeup1版本。
wait
wait让父进程等待子进程结束,并回收子进程的资源。它返回退出的子进程的pid,如果没有子进程或其他错误情况,则返回-1.
1 | |
wait()函数等待它的一个子进程终止。在exit()函数中,我们看到exit()只是关闭了进程打开的文件和从目录中退 出,但仍然保留了进程的信息,进程占据的内存和PCB都没有被释放,只是处于ZOMBIE状态。进程信息和内存 空间的释放由wait()来完成。
wait遍历过一次进程表,发现有子进程,但是都还没结束,那么它就调用sleep(curproc, &ptable.lock)进入休眠。这个休眠会被子进程在exit中,调用wakeup(myproc()->parent)来唤醒。
Part 2 是如何在xv6中实现Round Robin调度情况统计,统计用户进程的周转、等待、执行时间。
下一篇: Part 2