本文详解JOS操作系统虚拟内存的结构,以及内存管理单元的结构与实现。 在这次实验中,将探索以下问题:
- 计算机启动时如何开启虚拟内存
- 程序虚拟地址空间的结构
- 如何将内核物理地址与虚拟地址映射
- 访问一个虚拟地址的时候,会发生什么
- 如何管理内存空闲空间
- 如何保护特定的代码和数据
- ……
操作系统lab5: 内存管理
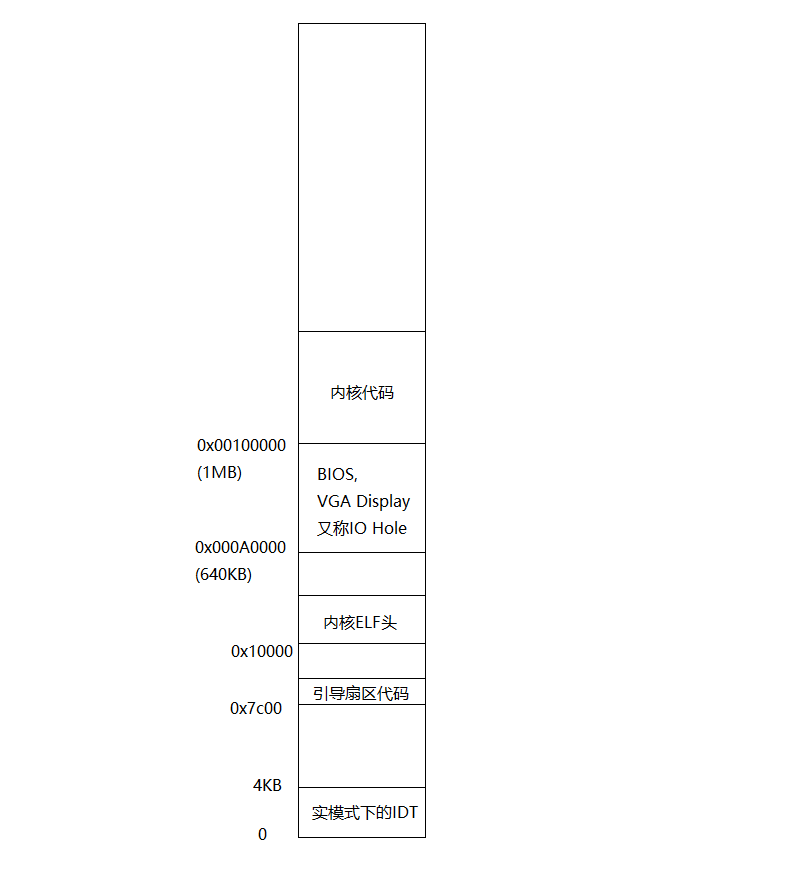
在lab1中,我们看到JOS 物理内存的结构:

最初物理内存只有1MB, 之后扩展到了4GB,这时物理内存的640KB 到1MB之间就成为IO hole,是不可用的,用来分配给外部IO设备,如上图,640KB 到1MB之间被分配给了VGA Display、BIOS ROM以及其他的外部设备,称为IO hole。在JOS中,从0x0到640KB这部分称为 basemem,是可用的, 1MB以上的空间称为extented memory,也是可用的。
为了更有效地管理和使用内存空间,JOS使用了虚拟内存,虚拟内存通过对程序存储地址与真实内存物理地址的解耦,有效解决了内存大小相对于大量用户程序所需空间不足的问题。引入虚拟内存之后,需要解决如何将多个程序分配到物理内存上,以及程序的虚拟地址如何与物理地址映射的问题。JOS通过分页的方式来管理内存和虚拟地址空间 ,将程序地址空间分为固定大小的页,将内存分为同样大小的页框,以页为单位将程序分配到内存物理空间上。页表记录了一个虚拟页对应的物理页框,以及这些页的相关信息,当程序执行中访问一个虚拟地址时,首先要访问它的页表,然后从页表中找到对应的真实地址,再访问真实的物理地址。
在操作系统中,页表的管理、从虚拟地址到物理地址的转换、页面的分配回收以及缓存的管理等等,都是由内存管理单元(MMU)来完成的。内存管理与虚拟内存对用户是不可见的。
在这次实验中,将探索以下问题:
- 计算机启动时如何开启虚拟内存
- 程序虚拟地址空间的结构
- 如何将内核物理地址与虚拟地址映射
- 访问一个虚拟地址的时候,会发生什么
- 如何管理内存空闲空间
- 如何保护特定的代码和数据
- ……
JOS的虚拟地址空间布局
在lab1中,我们追踪了开机时bootloader加载内核的过程,加载完成后,物理内存的布局为:(图片来自https://blog-1253119293.cos.ap-beijing.myqcloud.com/
 图片来自https://blog-1253119293.cos.ap-beijing.myqcloud.com/</img>
图片来自https://blog-1253119293.cos.ap-beijing.myqcloud.com/</img>
JOS用了手写的内存映射,将物理地址0x00000000-0x00400000之间4MB的空间映射到了虚拟地址0xf0000000-0xf0400000处。0xf0000000即为在虚拟地址空间中内核部分的起始。
真正开启虚拟内存之后,对于内核和用户程序来说,虚拟地址的布局在memlayout.h中定义:
1 | |
[KERNBASE, 4Gig ] : 这部分映射到物理内存上中断向量表、引导扇区代码、IOhole以及内核代码、数据。在这部分,一个虚拟地址 - KERNBASE就是它的物理地址。内核部分会被同样地映射到每个进程的高地址空间,用户是没有权限访问的。
KERNBASE往下是进程的地址空间,如之前报告中所述,进程地址空间的高处是内核栈,这部分地址是用户模式下不可访问的。
[MMIOBASE, MMIOLIM ] : 这部分空间属于内存映射的IO设备,与IO设备通信要陷入内核完成,因此用户模式也不可访问。
[UVPT, ULIM ] : 从ULIM往下直到UTOP是用户模式下只读的地址。UVPT到ULIM的这部分是当前的页目录,用户可以读取页表知道一个虚拟地址所在的物理页面,但不可操纵页表。
[UPAGES, UVPT] :这部分对应着pages数组在物理内存中存放的位置,用户也可以通过uvpt[n].pp_ref来知道某个物理页框是否已经被占用,但也不可操纵。
[0, UTOP] : 这部分才真正是用户模式下可以读写的地址空间,它包括了用户程序的代码段、数据段、堆栈等。
JOS中的三种地址
JOS中有三种地址: 逻辑地址(virtual address), 线性地址(linear address), 物理地址(physical address). 逻辑地址是程序编译链接之后变量的符号,实际上,逻辑地址是变量的段内偏移。 线性地址是逻辑地址经过保护模式的段地址变换之后的虚拟地址,线性地址=段首地址+逻辑地址。物理地址则是内存存储单元的编址,它会被直接送到内存的地址线上进行读写。
逻辑地址到线性地址的变换在保护模式下自动完成。如果没有开启页式地址转换(Paging),那么线性地址就是物理地址,如同我们在lab 1中,mov %eax, cr3之前看到的一样。如果开启分页,线性地址就会按查询页表的方式转换成物理地址。后面的实验内容中,我们直接将线性地址称为虚拟地址。
JOS的页表结构
页表记录了从虚拟地址到真实物理地址之间的映射,JOS的页表结构、虚拟地址组成定义在mmu.h中,它使用的是一个两级页表:
1 | |
地址最高10位表示页表目录,中间10位表示页表索引,最后12位表示在一个页面内的偏移,因此,页面总数为$2^{10}$ *$2^{10}$=1024x1024,页面大小为2^12=4096字节。
JOS使用两级页表,将全部的地址空间分为了一个页表目录和1024个页表,由于页表有1024个条目,每个条目的长度是4字节,则每个页表刚好就占一个页面,因此页表的地址只需要20位来区分。所以,在页面目录中,我们只需要20位来存放索引对应页表所在的物理地址,剩下的12位用来存放各种标志。页面目录中也含有1024条目,所以页面目录也只占一个页面。所以在用户的虚拟地址中,只需要存放一份页面目录的镜像,就可以让用户程序访问到页表,而不需要将所有1024个页表都映射到用户的虚拟地址空间。
一个页表目录条目(或者页表条目,一样的)的结构为:

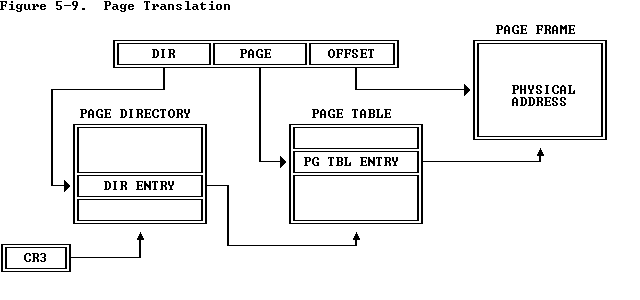
一个目录条目的前20位记录了一个页表的物理地址。访问一个虚拟地址时,首先根据前10位目录索引从page directory上找到相应的条目,取出前20位作为页表的物理地址,然后访问该页表,根据10位的页表索引找到页表上对应的物理地址(也是前20位,与PGSIZE对齐),这个20位的物理地址加上offset就得到了物理地址。如图:

条目剩下的低12位用来存放各种标志,来表示一个页表/页面的状态,所有的状态在mmu.h中定义:
1 | |
其中,Present位是用来判断对应的页表或者条目是否存在物理内存中,如果存在则为1. 在后面的代码中,我们判断一个虚拟页是否与一个物理页框映射,即是否驻留在内存时,就可以通过 entry & PTE_P来判断。
TODO 1: Physical Page Management 代码阅读
mem_init()
mem_init()在内核刚启动时调用,它的任务是在开机之后,设置好分页系统,并完成内核部分虚拟地址与物理地址的映射。目前只完成了一部分,它需要初始化的变量如下:
1 | |
kern_pgdir是页表目录。
PageInfo是一个用来描述物理页框的结构体,它定义在memlayout.h中, 由一个指向下一个节点的指针,和引用位构成。每一个物理页框都对应着一个PageInfo结构,引用位表示该页框是否已经被占用。pages数组记录了所有物理页框(总共npages个)的信息,而为了分配页面时更快地找到一个空的页框,JOS还维护了page_free_list链表,动态地保存所有空闲的页框。当需要分配页面时,从page_free_list的头部指针获取第一个空闲页框,然后将头部指针后移;当有新的空闲页面时,将这个新页面的指针添加到page_free_list中。
1 | |
mem_init具体实现如下:
1 | |
在JOS开机的时候,我们会看到一句输出:

给出了物理内存的可用空间,base是底部的basemem的大小(640K),extended是extended memory的大小,是1MB以上的可用空间。检测是在函数i386_detect_memory()中完成的:
1 | |
注意到读取basemem、extmem和ext16mem的大小使用了函数nvram_read。nvram_read实际上又调用了mc146818_read函数,这个函数通过IO端口0x70与0x71从实时时钟RTC中读取数据。RTC使用芯片mc146818,在系统电源关闭时,RTC仍保持工作,维护系统的日期和时间,当系统启动时,就从RTC中读取日期时间的基准值。时钟和这里的物理内存其实没有关系,但mc146818芯片中带有一个非易失性的RAM,也就是non-volatile-ram(nvram),系统的物理内存basemem和extmem的大小,都存放在这个芯片上,这样可以保证系统电源关闭时,这些信息不会被擦除。
i386_detect_memory通过nvram_read从mc146818芯片中读取出basemem和extmem大小(以KB为单位),然后根据它们计算出内存总的可用空间以及总的页面数npages,npages_basemem。PGSIZE定义在mmu.h中,为4096字节。
检测出可用内存大小之后,mem_init开始设置内核的页表。首先调用boot_alloc在物理内存中分配内核的页表。
boot_alloc()
boot_alloc()只会在JOS初始化虚拟内存之前被调用一次,之后分配页面的时候都只会使用page_allocator(). 之所以要写一个单独的boot_alloc是因为: 在启动时需要将内核的物理地址映射到虚拟地址,这种映射需要通过访问内核的页表来实现,创建页表涉及到分配页表所在的页面,可是分配页面又是在虚拟内存设置好才可以做到。所以,JOS使用了一个单独的boot_alloc,将需要分配的页面映射到一些固定的虚拟地址,并返回所分配的内容的起始虚拟地址。
1 | |
nextfree表示下一个未用的虚拟地址, 是一个静态变量。当mem_init调用kern_pgdir = (pde_t *) boot_alloc(PGSIZE)时,nextfree还未初始化,它会被初始化在内核.bss段的结束,并与页面大小4096B 对齐。
这里使用了函数ROUNDUP(char* a, uint32_t n),它同ROUNDDOWN一起在type.h中定义,分别是求 a/n的向上和向下取整,因此,ROUNDUP可以用来将地址a与n对齐。
用result保存nextfree作为起始地址后,将nextfree向后移动n个字节(也要和PGSIZE对齐),作为下次分配的起始地址。
在分配时,还要检查是否是一个合法的虚拟地址。 从上面JOS虚拟地址空间布局,我们知道nextfree-KERNBASE实际上就是nextfree的物理地址,这个物理地址不可超过内存可用的物理空间大小(页框总数npages*页面大小PGSIZE),否则抛出错误。
回到mem_init中,
1 | |
将内核页表分配在虚拟地址空间中内核.bss段的后面,然后用memset将页表初始化为全0.
1 | |
在虚拟地址布局中,我们看到从[UVPT, ULIM](大小为一个页表大小)这一段是用户和内核都可读的页表目录的复制,那么就要将虚拟地址UVPT映射到kern_pgdir的真实物理地址上去, 而要完成这种映射,就是要在kern_pgdir页表目录中,对应虚拟地址UVPT的条目中,将页表地址改为kern_pgdir的物理地址。 这样,当用户或内核访问UVPT与ULIM之间的虚拟地址时,就要首先访问kern_pgdir,查找uvpt对应的物理地址,然后发现该物理地址就是kern_pgdir所在的物理地址。
PDX(la)在mmu.h中定义,计算la对应的页表目录索引。PADDR是将传入的虚拟地址减去KERNBASE,得到物理地址。 PTE_U表示用户有权限(则内核也有权限),PTE_P表示物理地址存在。这个语句将页表目录中UVPT起始的页面对应的条目置为页表目录的物理页面地址, 并设置用户可读。
接下来,初始化pages数组,调用boot_alloc将它分配在内核页表目录kern_pgdir之后,并用memset初始化为全0.
1 | |
pages数组用来一对一地记录每一个物理页框是否被占用,可以通过pages[i].pp_ref来判断。
之后,mem_init调用page_init().
page_init()
我们已经初始化了页表目录和pages数组,则page_init()的任务就是初始化page_free_list,记录哪一些物理页框是空闲的,并设置pages中每一个页框的结构。
page_free_list实际上只是一个PageInfo结构体,此结构体中包含了指向下一个的指针,也就是下一个空闲的页框。所以,我们可以遍历pages数组,将那些已经分配出去的页框pp_ref置为1,将空闲的页框pp_ref置为0,并让page_free_list指向这个页框,从而将它插入空闲页框链表。
根据注释提示,第一个物理页框已经分配给中断向量表和其他的BIOS结构,basemem中剩下的部分([PGSIZE, npages_basemem*PGSIZE])还是空闲的。
extmem中,我们刚才已经分配了一部分给内核,要知道分配了多少,我们可以调用boot_alloc(0)来获取分配完pages之后,下一个可用的虚拟地址,将它减去KERNBASE得到物理地址,再除以PGSIZE就得到分配出去的页框数目。
IOhole部分,也就是从640KB到1MB之间的96个页面,都分配给了外部IO设备。IOhole和extmem是连续的,因此page_init的实现如下:
1 | |
page_alloc()
在pages设置好之后,分配页面就不可以再调用boot_alloc了,必须调用page_alloc通过在page_free_link查找空页框的方式来分配页面。page_alloc分配一个页面,返回该页面的PageInfo指针。它同时接收一个参数alloc_flags, 如果它的值为1(ALLOC_ZERO), 就将分配到的物理页面设置为全0。如果没有可用页框,则返回空指针NULL。所以该函数的步骤为:
- 从page_free_list中取出一个空闲页框的PageInfo结构体。
- 将这个页框从page_free_list中移去,并将链表头指针指向下一个空闲页框。
- 修改取出的PageInfo相关信息,如果有ALLOC_ZERO, 修改该内存页。
1 | |
其中,page2kva()函数是将传进去的result加上KERNBASE, 得到result的物理地址。 memset将result对应的物理地址开始,一个页面大小的物理内存设置为0.
page_free()
这个函数将一个被分配的页框归还,只有当该页框的引用位pp_ref为0时,才可以调用:
1 | |
assert是断言,用来判断条件是否满足,否则发出panic错误。当页框在page_alloc中被分配出去时,会将pp_link设置为NULL,而页框不再被使用时,pp_ref会置回0,只有这两个条件满足才可以调用page_free.
page_free只要简单地将页框插入到page_free_list的表头即可,为此,将pp_link指向现在的链表头部:page_free_list, 然后将头部指针指向该页框(pp).
TODO 2: Virtual Memory
参考pgdir_walk, boot_map_region 和page_insert函数,实现page_lookup和page_remove。首先阅读这三个函数的代码,为了方便解释代码,先看一下mmu.h中提供的一些宏,以及pmap.h中提供的功能函数。
宏与功能函数
在types.h中定义了与内存管理相关的类型:
1 | |
1 | |
对于一个虚拟地址va,如果它在KERNBASE以上,说明它是一个内核的虚拟地址,而内核部分是始终驻留在内存中的,我们可以使用pmap.h中定义的PADDR(va)直接将其减去KERNBASE得到物理地址。如果它不在KERNBASE上,那么就要通过MMU访问页表来将它转换成物理地址。相应的,如果是一个内核的物理地址pa, 才可以使用KADDR将它加上KERNBASE得到虚拟地址。
在mmu.h中,定义了一些宏,方便从一个虚拟地址获得对应的页目录、页表条目信息以及物理地址:
PGNUM(la): 表示一个虚拟地址的页编号,因为每个页是4096字节,又编号是从0开始顺序编号的,只要将la右移12位。PDX(la):对应页目录索引PTX(la): 对应页表索引PGOFF(la): 在页面内的偏移PGADDR(d,t,o): 从已知的页目录索引、页表索引和页内偏移还原一个虚拟地址。PTE_ADDR(pte): 从一个页目录条目或者一个页表条目中取出它的高20位物理地址部分。
在pmap.h中,函数page2pa()实现了给出一个页面,获取这个页面开始处的物理地址; 函数pa2page()实现了给出一个与页大小对齐的物理地址,返回它所在的页面的PageInfo。
pgdir_walk()
这个函数的功能是,给出一个虚拟地址va, 访问两级页表,找到它对应的页表条目,返回页表条目的指针。但是,由于页表不是一直都整个驻留在内存中的,所以va对应的条目所在的页表页可能还不在内存中,这时,如果create为False,就返回空指针,否则就要使用page_alloc()函数,分配这个页表页。
这个过程是:
- 从虚拟地址
va得到它的页目录索引 - 在页目录上根据索引找到对应条目
- 判断该条目的
present位是否为1, 如果置位,说明对应的页表在内存中,否则不在- 如果create置位,要在内存中为这个页表分配一个页框,使用
page_alloc().- 如果分配不成功,只能返回NULL。
- 分配成功,要将这个页表页的引用数pp_ref 加上1, 因为我们现在正要从页表上查
va对应的条目。并且,还要在页目录中,记录这个页表的物理地址,设置present为1,并设置权限为用户可读写。
create为0,返回NULL。
- 如果create置位,要在内存中为这个页表分配一个页框,使用
- 找到了页表后,计算
va对应的页表索引 - 获取页表上该条目,返回条目的地址。(这里所说的地址是该条目的虚拟地址)
1 | |
最后三行代码最为关键,经过上面的判断和分配页表页,现在该页表页的物理地址已经存放在页目录对应的条目中了, 用PTE_ADDR(*dic_entry_ptr)就可以从条目中取出该页表页的物理地址。用KADDR可以将物理地址转换为页目录的虚拟地址,这时,其实将page_base+page_off就可以得到该条目的虚拟地址了。因此,最后return &page_base[page_off]也可以替换为return page_base+page_off。
boot_map_region()
boot_map_region的功能是,将虚拟地址[va, va+size]映射到物理地址[pa, pa+size]上,意思就是在页表中[va, va+size]对应的条目中设置物理地址为[pa, pa+size]。 这里va, pa,size都是保证与页面大小对齐的,size的单位是页。perm参数给出了这块内存空间的权限。
这个函数是用来“静态“地映射UTOP以上的用户只读空间的。过程是:
- 遍历从[va, va+size]的每一个虚拟页,使用
pgdir_walk找到它在页表中的对应条目 -
将该条目的内容设置为 [pa , pa+size ] permPTE_P. 表示 present置位,这些页面存在于内存中,并设置了权限。
1 | |
page_insert()
这个函数是将一个物理页框pp映射到虚拟地址va上。要考虑两种情况,一是该va已经映射到了其他的物理页框上,这时就要接触这个映射关系; 另一种是该va本来就映射到pp上了。过程是:
- 调用
pgdir_walk得到va在页表上的条目。 - 如果找不到该条目,说明内存不足,返回错误码
-E_NO_MEM。 - 要先让
pp->pp_ref++,之后解释原因。 - 如果该条目已经存在,说明
va本来已经映射到一个物理页框上,tlb_invalidate使该va对应的页表条目失效,这样,才不会使进程在这个过程中访问到不正确的物理地址。这是因为进程会缓存它用到的页表,快速访问页表时,它先访问缓存中是否有该页表,如果没有,才从页目录去找。page_remove解除va和原来物理页框的映射。
- 无论之前该条目是否存在,现在
va已经不与任何物理页框绑定,将条目内容设置为pp的物理地址,设置present为1,并设置权限为perm
1 | |
在这个函数中,只用(*entry) & PTE_P判断页表条目是否存在,来判断va是否已经有映射关系,但没有区分va是否与pp映射。如果我们将pp->pp_ref++移到if块后面,那么当va已经与pp映射时,pp原来的引用数有可能为0,在if中,我们会不加判断地调用page_remove,然后因为引用数为0,直接调用page_free将它释放掉。 既然释放了,它就会处在空闲链表page_free_list中,pp_ref应该保持为0. 我们之后再用pp->pp_ref++时,就会让空闲链表管理出错,下一次分配页框时,可能在空闲链表中找到这个pp,但它是不可用的。
接下来我们实现page_lookup和page_remove函数。
page_lookup()
这个函数的功能是给出虚拟地址va,找到它映射到的物理页框。如果传入的pte_store不为NULL的话,就将该虚拟地址对应的页表条目指针存放到pte_store中。实现过程是:
- 调用
pgdir_walk找到va对应的条目,这里create应该设置为0,即若va所在的页表页不在内存,我们也不分配它。 - 如果返回的是NULL,表示va所在的页表页不在内存,即
va现在没有映射到物理页框,返回NULL。 - 如果
va对应的页表页在内存中,但是条目的present位为0,说明va没有映射到物理页框:- 判断
pte_store,如果不为NULL,将条目存放在pte_store中 - 返回NULL
- 判断
- 用
PTE_ADDR从条目上获得va对应的物理地址 - 用
pa2page获取物理地址对应页框的PageInfo - 如果
pte_store非空,将pte保存,最后返回PageInfo
1 | |
page_remove()
这个函数的功能是解除va与它对应的物理页框之间的映射关系。这不一定说明该物理页框已经空闲,可以回到空闲链表中被分配。因为该页框的引用数并不一定为0,例如在共享内存时,有可能不同进程会共享一部分物理内存,不同的虚拟地址会映射到同一个物理页框上。因此,这个函数的实现过程应该是:
- 调用
page_lookup查找va对应的物理页,并保存其页表条目的地址在&pte中。 - 如果该
va有映射到某个物理页框,解除映射:- 调用
page_decref,这里面做的是,将pp_ref减去1,如果等于0,可以调用page_free释放空间,将页框归还。 - 因为使用快速页表访问时,进程可能缓存了最近使用过的页表条目,所以要调用
tlb_invalidate让这条va的缓存条目无效,否则进程会优先访问缓存中的条目,进而访问到非法的物理地址。 - 将
va对应的条目内容清0.
- 调用
1 | |
检查
pmap.c中实现了几个函数对代码进行了检查。这些检查函数在mem_init中被调用,其中check_page()是检查分页的基础功能是否已经实现好,包括page_alloc(), page_insert(), page_remove(),page_lookup(), pgdir_walk() 以及page_free()。
重新编译并启动qemu,看到控制台输出:
” check_page() succeeded!” 表明实现是正确的。
TODO 3: Kernel Address Space
###完成mem_init()
上面的函数已经完成了分页机制,页表也已经创建好。现在,我们就可以通过修改页表上的条目,完成UTOP以上用户不可操作的空间与物理地址的映射。
首先,将[UPAGES, UVPT]这部分虚拟地址映射到pages数组上,权限设置为内核与用户只读,相当于为用户保留了物理页框信息的拷贝。这样,虚拟地址空间上实际有两份pages,一部分在KERNBASE以上,用户不可见,内核可读写,这一份就是在mem_init刚开始分配的pages;另一份是为用户准备的只读拷贝,两者通过页表映射到同一片物理内存上,但这份拷贝设置的权限是只读,所以用户不能对这部分虚拟地址的内容进行操作;又因为用户不可访问KERNBASE上面的虚拟地址(在用户访问虚拟地址时,内核会判断虚拟地址是否超出ULIM),所以用户不可读写pages。这样就实现了对pages数组的保护。
这个映射用
1 | |
来实现。
然后要完成内核栈的映射。从[KSTACKTOP - PTSIZE, KSTACKTOP]这部分都属于内核栈, 但被分为两个部分,上面[KSTACKTOP-KSTKSIZE, KSTACKTOP]是真正的内核栈,与某些物理页框映射,而[KSTACKTOP - PTSIZE, KSTACKTOP-KSTKSIZE ]不与物理地址映射,只是用来防止内核栈向下增长的时候发生溢出,然后覆盖了Memory-mapped IO部分,称为保护页。如果内核栈溢出,它就会发现物理地址不存在,抛出错误。
1 | |
内核栈是内核可读写,但用户不可见的,这些页面的权限要被设置为PTE_W。调用boot_map_region, 将KSTACKTOP-KSTKIZE开始到KSTACKTOP的虚拟地址映射到bootstack的物理地址上,大小如上面结构所示,为KSTKSIZE,但要注意使用ROUNDUP与页面大小对齐:
1 | |
将整一个[KERNBASE, 2^32)的整个内核地址空间映射到内存的[0, 2^32-KERNBASE),权限是内核可修改但用户不可见。我们知道KERNBASE的虚拟地址是0xf0000000, 而整个虚拟空间的大小是2^32也就是4G,所以内核的大小总共是256MB=0X10000000,这已经是与页面大小对齐的。 内存将一直有256MB的空间被内核占用。调用boot_map_region实现如下:
1 | |
检验
重新编译,启动QEMU,所有的检查都已经通过,说明分页机制与内核的分配已经正确实现:
总结
分页机制建立和开启全过程:
完整地阅读mem_init,
1 | |
内核部分虚拟地址空间的初始化全过程是:
-
检测总共可用的物理内存大小,由
basemem+extmem构成,记录总页数npages和低地址页数npages_basemem -
要初始化内核虚拟地址,必须通过页表来映射,但一开始,页表还不存在,页表的虚拟地址也还没有映射。因此,首先要分配页表目录的虚拟地址。这个分配无法通过分页机制来完成,只能通过静态映射:
kern_pgdir = boot_alloc(PGSIZE). 页目录分配好后,首先初始化为全0. -
因为用户进程在访问虚拟地址时,需要访问页表,因此我们需要在ULIM以下为用户准备一份页表的只读拷贝。然而,总共1024份页表的开销较大,其实只要能够访问到页目录,就可以通过页目录访问到页表。 而我们甚至不用真的在内存中存放两份页目录,只需要将拷贝的虚拟地址也指向
kern_pgdir的物理地址即可。 所以,我们在页目录上让UVPT条目指向页目录本身,并设置用户只读:kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;, 结构如图: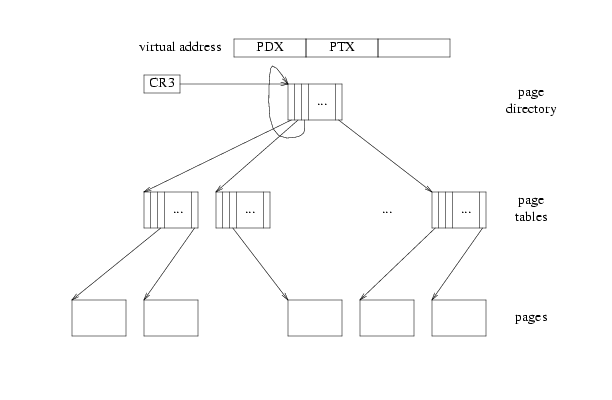
- 这里CR3寄存器存放的是进程页目录的虚拟地址。操作系统中有内核页表和进程页表两种页表,进程页表是每个进程独自有一份的,页目录的虚拟地址存放在cr3寄存器中,当进程切换时,会加载页目录虚拟地址到cr3寄存器。进程页表既包含了用户态,也包含了内核态的虚拟地址,内核态的虚拟地址是所有进程都一样的,就是内核页表的拷贝,它的虚拟地址就在
UVPT,大小为一个页面。
-
拷贝好内核页目录后,因为接下来涉及到管理物理内存,需要记录每个页框的信息,这些信息保存在
pages数组中。同样,需要用boot_alloc将pages静态映射到一片虚拟地址。如果打印出pages和kern_pgdir的虚拟地址,可以看到他们的虚拟地址分别是f0119000和f0118000, 是在f0400000之内的,这两个数据结构已经在物理内存中了。 -
将
pages初始化为0,然后用page_init将已经分配出去的物理页框引用位置为1,并将空闲物理页框添加到page_free_list链表中,接下来,内核就可以使用page_free_list和pages两个数据结构管理物理页框。 -
允许用户读取
pages来知道内存的占用情况,但为了保护该数据结构,同样要在ULIM以下为它保留一份拷贝,这份拷贝在UPAGES到UVPT之间,用boot_map_region来进行映射。 -
boot 的时候, 已经为内核初始化了一个栈,栈顶的界限是
bootstack,用boot_map_region将虚拟地址的KSTACK部分映射到bootstack所在的物理内存上,进程进入内核态,并进入公共部分时,实际上运行在这个内核栈上。 -
最后,把整个高地址部分的内核虚拟空间映射到物理内存0地址开始处,实际上是内核部分一直驻留在内存中,且内核的虚拟地址空间被拷贝到每个进程的高地址部分。
-
lcr3(PADDR(kern_pgdir))是把内核页目录基址放在cr3寄存器中,之后如果开启分页,访问虚拟地址时,就会从cr3加载页目录地址,从而访问页目录。 -
将控制寄存器cr0置位为:
CR0_PE|CR0_PG|CR0_AM|CR0_WP|CR0_NE|CR0_MP ,~(CR0_TS|CR0_EM)各个字段含义如下:-
1
2
3
4
5
6
7
8
9
10
11#define CR0_PE 0x00000001 // Protection Enable #define CR0_MP 0x00000002 // Monitor coProcessor #define CR0_EM 0x00000004 // Emulation #define CR0_TS 0x00000008 // Task Switched #define CR0_ET 0x00000010 // Extension Type #define CR0_NE 0x00000020 // Numeric Errror #define CR0_WP 0x00010000 // Write Protect #define CR0_AM 0x00040000 // Alignment Mask #define CR0_NW 0x20000000 // Not Writethrough #define CR0_CD 0x40000000 // Cache Disable #define CR0_PG 0x80000000 // Paging - cr0被设置为,开启保护模式,保护模式开启时只是开启了段级保护,没有开启分页,即逻辑地址转换成线性地址,线性地址直接等于物理地址, CR0_PG开启分页,CR0_AM 开启地址对齐检查, 开启写保护, 开启协处理器错误, 开启监控协处理器。TS任务已切换标志为0,EM为0,表示有协处理器,会将浮点指令交给协处理器用软件来模拟。
-
-
完成。
如何保护内核数据和代码:
- 通过虚拟地址空间的隔离。检查用户访问的虚拟地址与
ULIM,可以防止用户访问高地址。 - 为
ULIM以下的每个页面设置权限,并启用cr0中的非法写保护,可以防止无权限用户修改只读页面。
如何管理内存空闲空间,以及管理的开销:
- 通过一对一地维护每个页框的信息,并动态维护一个空闲页框链表(头指针)来实现。
- 每个页框PageInfo的大小是8B,
pages的大小是PTSIZE=4MB, 总共可存放512K个PageInfo,即可维护512K个物理页,总共512K*PGSIZE=2G物理内存。 - 如果全部2G的物理内存都分配出去,那么维护的开销是,
pages大小+kern_pgdir大小+所有页表页大小=4MB+4K+2MB的额外内存。
推荐阅读: OS操作系统实验 xv6调度算法实现