基于个性化注意力机制的新闻推荐
论文链接:https://arxiv.org/pdf/1907.05559.pdf
这篇论文是2019年SIGKDD的7篇精选论文之一。主要解决的是新闻推荐中个性化的问题。
Introduction
首先介绍了为什么需要新闻推荐(减少信息过载,高效获取信息)
新闻推荐有什么样的难题(可以归结为如何表示新闻,以及如何表示用户兴趣):
这篇论文的作者之前已经做过一项工作,就是多视角学习的新闻推荐,所谓多视角,就是用标题、内容、类别和子类别分别去表示一篇新闻,结果是类别和子类别获得了最高的attention权重。但是在这一篇论文中,作者选择了用标题来表示新闻,原因可能是,相比内容标题更短代价更小,但是相比类别又具有更多潜在信息。
但是,一个新闻标题中,并不是所有词汇都同样关键,例如That 和 Crazy的重要程度就显然不同,因此可以引入基于单词的注意力机制, 也就是给不同的单词不同的权重,来捕捉关键信息。
对于第二个问题,也就是如何对用户兴趣建模,每个用户虽然点了很多篇新闻,但是,他们不是对这些新闻都同样地感兴趣,不同的新闻对用户兴趣的建模关键程度也不同。这样就可以引入一个基于新闻的注意力机制来解决。
然后作者列举了已有的一些新闻推荐模型,这些模型有的也有使用attention机制来识别关键因素,但是这些attention网络都是静态的,都无法做到权重根据用户来调整。
不同单词对新闻内容表示的重要程度,以及新闻对用户兴趣表示的重要程度,都是因人而异的。不同的用户看到一样的标题,他们的关注点可能不同,点击了同样的几篇文章,他们对同一篇文章的感兴趣程度也不同。因此,这两层的注意力机制还必须是个性化的,才能解决个性化推荐的问题。
NPA模型
模型分为三个部分:
- 编码新闻的news encoder
- 编码用户兴趣的 user encoder
- 预测点击新闻的概率的click predictor
news encoder和user encoder中都使用了word-和new-两个层级的注意力网络,并且注意力网络的权重是个性化的, 相同单词、相同新闻对每个用户的权重可能不同。
News Encoder
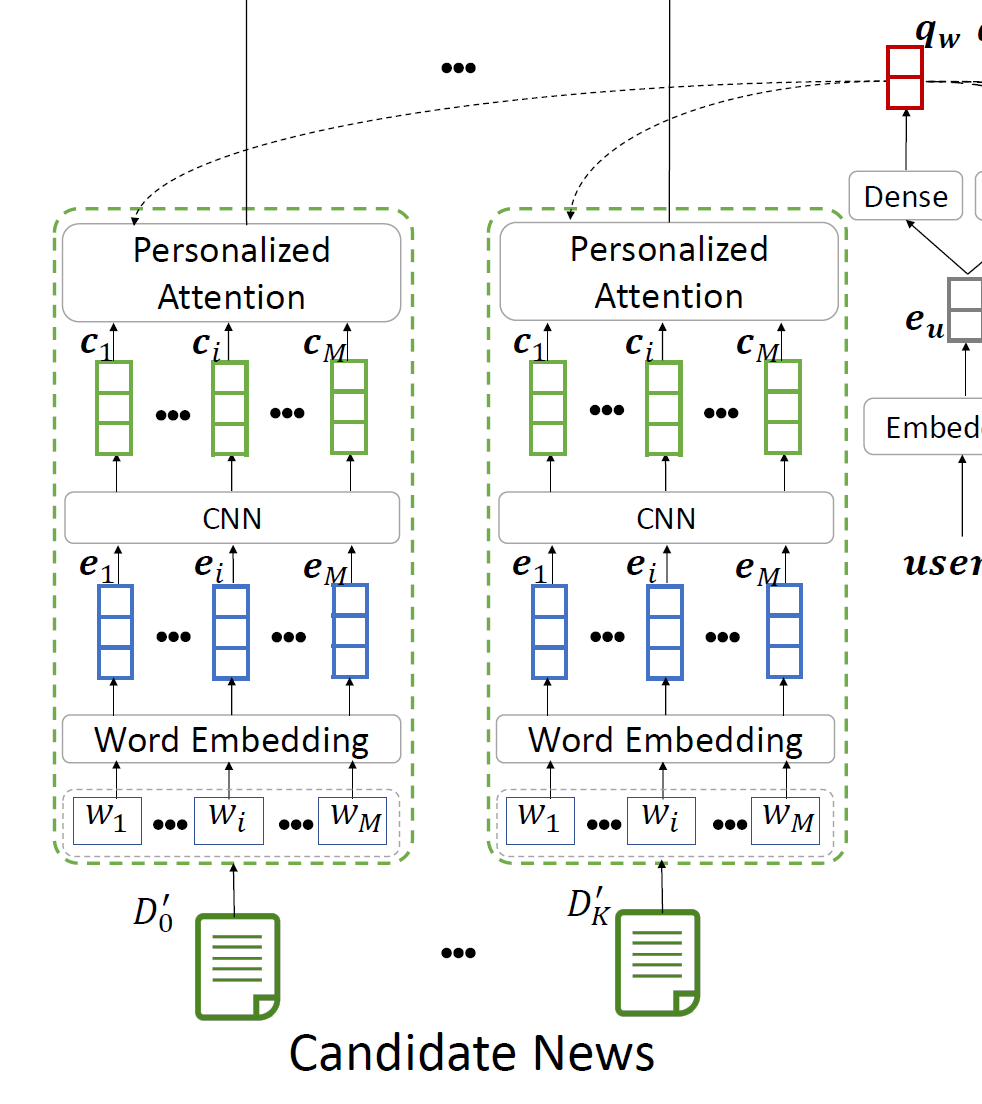
根据新闻的标题来编码一篇新闻。分为3个子模块。
- word embedding(word2vec算法)
- NLP中的最小单位是单词,单词组成句子,句子再组成文章。而神经网络只能接受数值性输入,因此要将自然语言的单词转换成数值向量,就是word embedding的过程。
- skip-gram方法:
- 输入一个单词x,预测它的上下文y;x的表示形式用one hot encode,V是词典的大小,则输入的向量就是V维的。从x到输出f(X)是一个有一个隐层的神经网络,但是隐层是线性的,没有激活函数! 输出也是V维的,输出是x的上下文是这V个单词的概率。
- 在训练完成之后,得到神经网络的权重(输入到隐层,隐层到输出层)分别是输入向量和输出向量,输入向量的维度则和隐藏层节点个数相同,因为x只有一个节点是1,其他都是0,所以输入到隐层节点的权重不会每一个都一样(否则输出就会一样),所以可以用输入向量(或者输出向量)唯一表示一个单词。这样相当于将V维的输入降维。
- 论文里说用一个V*D维的word embedding矩阵来做word embedding,D的维数为300, 这里用的是已经预训练好的GloVe矩阵
- CNN: 用来观察标题中的每一个局部,发掘出局部中隐藏的信息。这个卷积层的意义是,让每一个词的表示向量不仅包含这个单词本身的信息,还要包含窗口为2k+1的上下文信息。
- 这个卷积就只是一层\( N_{f} \)个卷积核,加偏置B(B的维度就是Nf维),然后用Relu激活)。
- window size = 2k+1,\( \mathbf{e} \)是word embeddings连接起来得到的矩阵。输出是\( c_{1} \cdot \cdot \cdot c_{m} \),是包含了上下文信息的词表示向量。
- Word Level Attention Network: 这是这个模型的重要特点之一,这里体现了个性化的注意力机制。因为每个用户在标题中对每个单词的关注度是不同的,所以attention 网络就不能像传统的注意力网络一样,对每一个用户有相同的query vector。这里使用的方法是:
- 先将用户的ID进行embedding变成一个De维的向量\( e_{u} \)( 这里的问题,user ID不是单词是各种符号的集合如何embedding? )
- 再将用户IDembedding向量,经过一个单层的网络映射成preference query vector。这个网络有一个Relu激活: (fig3中的红色向量)
- 每一个词表示向量的权重计算是:综合了词表示向量和query vector。 (fig3中的橙色向量就是权重向量α)
- 最终,新闻表示就是所有词表示的加权和:
User Encoder
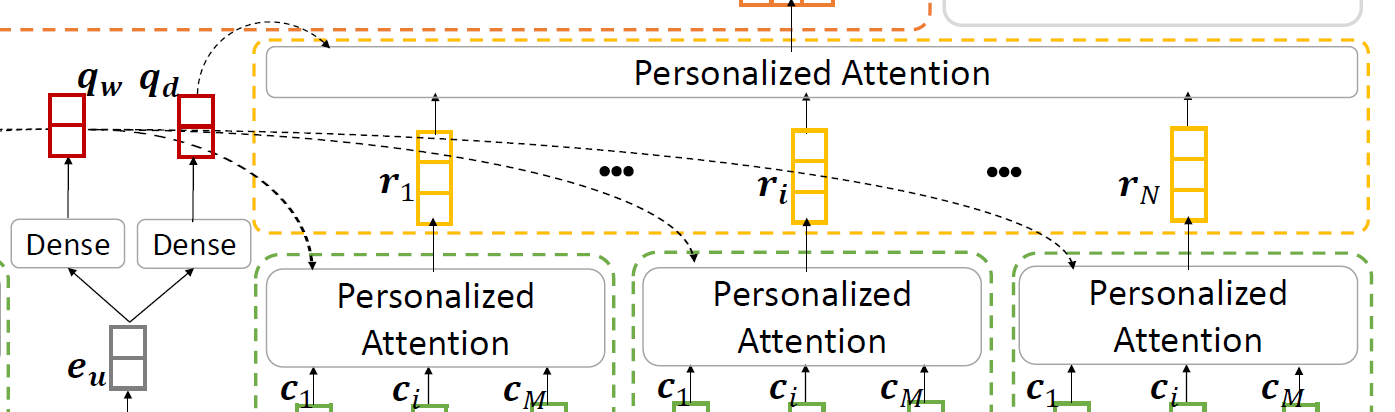
- user encoder是对于一个用户,将所有他点击过的新闻(用该用户的ID embedding进行word attention 之后得到的新闻表示)作为输入,经过一个news level attention 网络,得到该用户的表示。
-
个性化attention网络的思路跟前面差不多,还是利用了user ID embedding,生成另一个query vector:
-
query vector qd 和 ID embedding 内积得到新闻表示的权重向量,用同样的方法:
- 最终,用户的表示向量 \( \mathbf{u} \) 是该用户点击过的新闻表示向量加权和。
Click Predictor
在新闻推荐中,因为用户会在看到的大量新闻中,只点击其中非常少数的新闻,所以在这个问题中,正负样本是非常不平衡的,如果直接在所有candidate新闻样本上预测,训练效果显然不好,并且训练过程要花费很多时间。
因此,提出一种正负样本平衡的训练方法,即联合预测K+1个样本,其中有K个负样本,1个正样本,预测每一个样本的click score:
预测值yi用 新闻的表示和用户表示向量的内积得到,得到的yi值 要在K+1个样本中softmax归一化。
这样,整个predictor就可以看成是一个伪二分类问题,可以使用交叉熵loss函数来训练,loss function是:
只考虑正样本的损失值
这样,模型从predictor到最底层的attention、CNN的参数,都是可以用back propogation来调节的。这里使用Adam来优化。
实验
数据集
数据在MSN新闻上采集,具体情况看table1,正负样本的比例是13. 这一小节还具体列举了模型一些超参数的设置。 测试集采用最近一个星期的数据,另外随机采样了10%的数据作为验证
其中,user embedding(用user ID得到的)维度是De=50, 两个查询向量 的维度Dq和Dd的维度都是200.
metrics:
- AUC: AUC的涵义是ROC曲线下的面积。 TPrate是指,真值为1 的数据被模型预测为真的频率, FPrate是指,真值为0的数据被模型预测为真的频率。 ROC曲线的纵轴是TPrate,横轴是FPrate。 如果曲线是y=x,那么说明无论真值是0还是1,模型都以一样的概率预测为真或假,说明模型毫无辨别能力。 AUC则是ROC曲线下的面积,一般来说要在一定的FPrate下,TPrate越高越好,那么面积就要越大越好,最坏的情况就是0.5. AUC的好处是同时考虑了模型对正例和负例的预测能力,可以规避正负样本很不平衡时带来的问题。
-
MRR: 用来评价搜索算法的一种指标,如果第n个结果匹配,得分为 1/n , 最后得分为总和。
-
DCGp: 是用来评价搜索算法排序好坏的一种指标,要人为地将结果分为几个等级,每个等级对应一个分数,然后分数根据排序位置衰减,最终DCG分数是p个结果得分的总和(论文里面有预测5个的也有预测10个的分数,10个分数肯定是更高的)
-
nDCG: 是相对DCG,是先将人工排好序的结果作为理想状态,计算此状态下的IDCG,然后用预测得到的结果除以IDCG,得到相对的nDCG。
实验结果
- 有使用神经网络的模型比使用矩阵分解的传统算法效果好
- 使用了negative mining的算法比不使用的算法效果更好
- 使用attention 机制的算法也普遍比没有使用的要好,因为新闻中的不同词以及不同新闻对于新闻本身以及用户兴趣的表现重要程度确实不同。
- NPA算法在被比较的算法中表现最好。