论文题目:Please Forget Where I Was Last Summer:The Privacy Risks of Public Location (Meta)Data
链接:
Please Forget Where I Was Last Summer:The Privacy Risks of Public Location (Meta)Data
Abstract
这篇文章研究用户在社交网站,例如推特上的位置数据,如何以及多大程度上泄露了他们的隐私(例如敏感信息,身体状况等)。他们制作了一个LPAuditor的工具,这个工具可以解释性地评价社交位置元数据(location metadata)造成的隐私泄露。
这个系统首先可以以最细的粒度发现用户的关键位置(通过鉴别他们真实的邮件地址(postal addresses). 然后,他们可以自动地进行隐私信息推断, 比如发现用户去过的和健康相关的位置、宗教场所以及夜店等。
作者们还进一步探索了用户活动和暴露出来的信息失配的情况。他们发现老版本的推特app,会给用户的geo-tagged的推文加上精确的GPS 坐标(在元数据里),这种做法是会侵犯用户隐私的。而当用户对自己的数据有更多选择,例如可以选择他们要发表什么粒度的location data时,这种细粒度带GPS坐标的推文94%都不会被发表,说明用户对自己精确的位置信息是十分在意的。
所以,这个LPAuditor可以给用户作为一种审核工具,告诉用户在发表这个位置信息的时候,他们的什么隐私可能会被暴露,从而让用户对自己的数据有更多选择。
(location metadata指的是用户发布的推文的位置属性(并不是用户自己打上的位置tag,而是保留在系统后台的属性数据,这种数据是对后台或者API可见的。)
Introduction
首先讲社交网络上发布位置信息可能带来什么后果: stalking、cybercasing, cybercasing是指从用户发布的位置信息中推断出家庭住址并且推断出什么时候用户不在家,从而实施抢劫。
之前的研究present了如何从用户的数据推断出用户的关键地址(家庭、工作地址等),但是却没有指出用户具体推文中的位置信息会导致的隐私泄露程度,也没有进一步探索这些推文可以进一步(自动地)推断出什么其他的敏感信息(这些研究有探索能进一步推断出的消息,但并不是用算法去自动推断,也没有实现出来)。
作者present 了 LPAuditor工具。最初是一种鉴别用户家庭和工作地址(postal address的粒度)的技术,是用两级的聚类来做的,把推文进行聚类,然后把这些聚类映射到某个postal address上,这样做,对于那些用户移动带来的空间移位以及GPS错误的情况会比较鲁棒。 然后是对某个用户推文的时空特征进行分析,推断关键位置。在这个任务中, 数据集真值是手动构建的。
然后他们研究那些会暴露用户在某些敏感地点的推文。这里的敏感位置指的是和三个方面有关的位置: 医疗健康、宗教、性/夜生活。 他们发现,有71%的用户在敏感地点发布过推文, 27.5%的推文可以从内容中推断出他们处于敏感位置。 当用户的推文中包含了更多的情境时,位置元信息就会泄露更多的隐私,例如用户推文中提出她在见医生而位置元信息显示在一个堕胎诊所。 不仅是推文内容,单单从分析时空特征的模型,也可以发现29.5%的用户正在敏感位置。
注意到这种隐私侵犯对用户是不可见的,因为GPS坐标这种元数据只能在推特后台或者用推特API 得到,而且历史数据会一直对API可见,当用户的关键位置被成功精准发现时,这种隐私政策带来的隐私暴露会增加15倍。
(这篇文章的写作真是长句好多……看起来太费劲了……)
SYSTEM OVERVIEW
1. Data labeling and Clustering
1.1 labeling tweets:
首先要把每一条推文的GPS坐标与一个postal address对应起来。这个可以用公共的API,使用ArcGIS和Google Maps Geocoding
因为数据集很大,调用API是比较不经济的。所以提出了一种caching机制,就是每当要label一个坐标时,查找附近有没有已经label好的,如果两个坐标距离小于二米,就判定他们属于两个地址。(这样会不会引入误差呀?例如在街上两个店铺有可能距离会小于两米的(聚类的时候有矫正误差))这种方法将调用次数减少到42.5%
但是有一些地方API是给不出地址的。这些地方主要是大学校园、机场或者是偏远山区等。把这些label为unknown address,并不影响判断的精度。
1.2 initial clustering
首先是把属于同一个postal address的推文聚到一类,计算这个聚类的中心坐标,作为该postal address的中心坐标。
但是,caching机制会引入一些误差,所以作者比较了Google API返回的中心坐标和聚类得到的,如果不一样,那就采用google的作为中心坐标。但这种矫正只是对每个用户最大的那10个聚类做而已,其他的不重要。
对于那些标记为unknown的,使用DBSCAN算法。
DBSCAN算法:
转自:
一种基于密度的聚类算法,基于密度的聚类算法一般假定类别可以通过样本分布的紧密程度决定,如果是同一类别的样本,他们之间是紧密相连的,就是说在一个类别里的样本,周围不远处一定有同类样本存在。
假设我的样本集是D=(x1,x2,…,xm)则DBSCAN具体的密度描述定义如下:
| 1) ϵ-邻域:对于xj∈D,其ϵ-邻域包含样本集D中与xj的距离不大于ϵ的子样本集,即Nϵ(xj)={xi∈D | distance(xi,xj)≤ϵ} 这个子样本集的个数记为 | Nϵ(xj) |
| 2) 核心对象:对于任一样本xj∈Dxj∈D,如果其ϵϵ-邻域对应的Nϵ(xj)Nϵ(xj)至少包含MinPts个样本,即如果 | Nϵ(xj) | ≥MinPts,则xj是核心对象。 |
3)密度直达:如果xi位于xj的ϵ-邻域中,且xjxj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达, 除非且xi也是核心对象。
4)密度可达:对于xixi和xjxj,如果存在样本样本序列p1,p2,…,pT满足p1=xi,pT=xj 且pt+1由pt密度直达,则称xj由xi密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,…,pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
5)密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的。
DBSCAN算法是由密度可达关系导出最大密度相连的样本集合,就是一个聚类。
这个DBSCAN的簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的ϵ-邻域里;如果有多个核心对象,则簇里的任意一个核心对象的ϵ-邻域中一定有一个其他的核心对象,否则这两个核心对象无法密度可达。这些核心对象的ϵ-邻域里所有的样本的集合组成的一个DBSCAN聚类簇。
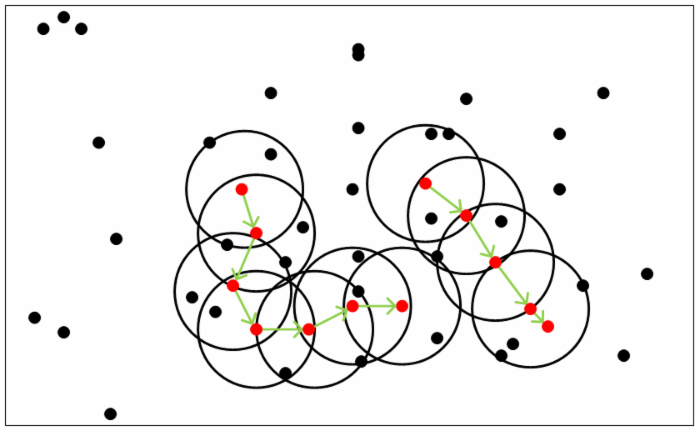
算法过程:
- 确定好参数ε和MinPts,初始化核心对象集合为空集,初始化聚类簇数k=0,为访问样本集等于全集,簇划分C=空集
- 对于每一个样本点:
- 通过规定的距离公式,找到样本点的ε-领域子样本集
- 如果子样本集中个数满足MinPts限制,它就是核心对象样本,加入核心对象样本集合。
- 如果核心对象集合是空集,那算法就结束了,所有的点都是噪点或者单独一个聚类
- 在核心对象集合中,随机选择一个O作为初始,当前簇的核心对象队列Ωcur={o} ,初始化类别序号k=k+1, 初始化当前簇样本集合Ck={O}, 未访问样本集合更新。
5)如果当前簇核心对象队列Ωcur=∅,则当前聚类簇Ck生成完毕, 更新簇划分C={C1,C2,…,Ck}, 更新核心对象集合Ω=Ω−Ck, 转入步骤3。否则更新核心对象集合Ω=Ω−Ck。
6)在当前簇核心对象队列Ωcur中取出一个核心对象o′,通过邻域距离阈值ϵ找出所有的ϵ-邻域子样本集Nϵ(o′),令Δ=Nϵ(o′)∩Γ 更新当前簇样本集合Ck=Ck∪Δ, 更新未访问样本集合Γ=Γ−ΔΓ=Γ−Δ, 更新Ωcur=Ωcur∪(Δ∩Ω)−o′,转入步骤5.
输出结果为: 簇划分C={C1,C2,…,Ck}
简单总结就是,先找出所有核心对象,然后初始随机选择一个,它的邻域中的样本全部加入这个聚类,其中的核心样本加入队列,然后每次从队列中取出一个样本,重复上述过程,直到队列为空,这样就得到一个簇聚。 得到之后,再随机选择下一个核心对象作为另一个聚类的初始样本,再继续。
在这篇文章中,作者将距离阈值设置为30米。
Second-level clustering
第一次聚类之后,就会发现在同一个地点范围之内,会出现不止一个聚类,通常都是一个大的聚类,然后旁边有一些非常小的,而且非常靠近的聚类。作者把这些坐标在地图上标出来,但也很难确定他们属于哪个地址,这是由多种因素造成的: 1. GPS读数不精确;2. API也有一定误差; 3. 与用户在发送推文时候的位置有关,例如用户正在离开或到达那个地方,或者在后院或隔壁。
使用改进的DBSCAN方法来把这些小的聚类和大聚类合并,原则是距离不能超过50m。因为DBSCAN是会把密度相连的样本作为一类,也就是级联效应(cascading effect),改进就是在加入聚类的时候都要check这个聚类和大聚类的距离是不是50m以内。
(这个2次聚类是说对第一次的DBSCAN聚出来那些unknown address 的类再聚类,还是那些精确的地址也要加进来呢?)
2. Identifying Key User Locations
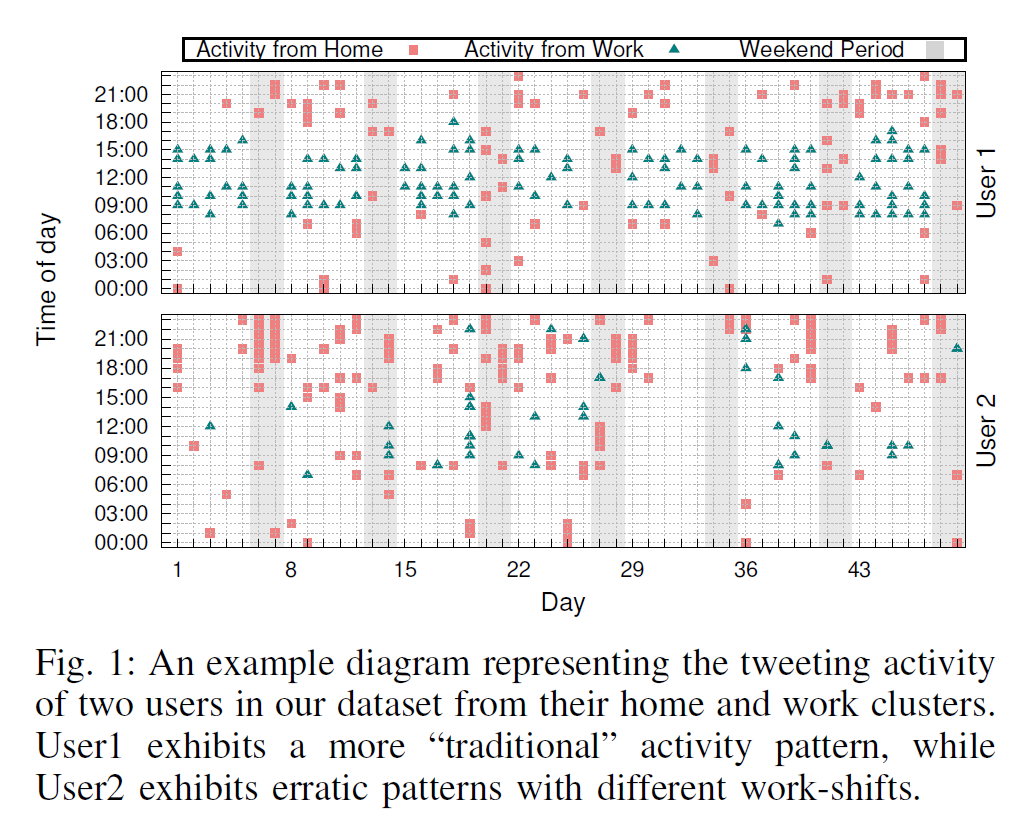
在鉴别哪些聚类是用户的关键位置时,没有用到推文中的内容和语境信息,而是单纯用时序特征, 而这是基于人类社会活动的一般规则,例如8小时上班制,但对于那些上班时间很不规律的地区就不在研究范围之内了。 而之所以不用推文内容,是要强调隐私泄露的风险: 即使你很小心,在推文内容中避免了关键位置信息的透露,你的GPS坐标也会出卖你。
Home
基于两个inituitions:
- 在这个鉴定为home address 的聚类中,要有比较多的推文,因为用户每天都会在家一段时间。
- 在别的地方可能会有非常有规律的时序模式,但是在家发推文的时间就会比较分散,从很早到很晚都可能。
而在工作日的时候,这些特征可能会和其他地点的活动混淆,只在weekends观察会更鲁棒。
他们的方法是首先找到5个周末里面推文最多的聚类,然后估计了time frame 和active hours, 选择其中time frame最长的。
work
在工作地点发推特在时间上比较有规律。
首先也是找5个推文最多的聚类,去掉已经标记为home的,然后对每个聚类, 看发推文超过一条的那些天,将第一条和最后一条之间的间隔作为time frame, 然后把这些time frame叠加起来,如果某个time frame在这个聚类超过一半的日期里都有表现,就将这个time frame作为prominent time frame。 这样可以消去一些噪音,例如用户某天加班了,也可以考虑到一些几班倒的用户。
然后,将dominant time frame以外的推文删掉;并且去掉time frame经常超过10小时的聚类(这是根据US法定工作时间和欧盟一周48小时限制)。不过考虑到有些人就是会加班,所以只是把超过20%time frame大于10小时的聚类去掉。
可以看到,这个算法比起传统的固定工作时间的算法要灵活许多。
3. Identifying Highly-Sensitive Places
任务: 鉴别用户的Potentially Sensitive Clusters(PSCs),这些聚类附近有比较敏感的场所,并且确定用户是否去过这些场所。
关于聚类附近是否有敏感场所,使用Foursquare‘s venue API来获取聚类附近场所的信息,附近指的是聚类中心坐标25米范围内。
Content-based:
聚类离敏感场所近不代表用户去过那些敏感场所,需要推文内容佐证。佐证使用的是一个手动构建的wordlist,包括医疗、宗教、sex/nightlife的关键词。
首先对推文进行预处理:去掉emoji、mentions、停顿词、url,tokanization、lemmatization。
然后使用tf-idf方法(term frequency - inverse document frequency)来统计关键词频率。
tf-idf:
一个挺简单的算法:
在这里,作者是将这个聚类的所有推文作为一个document,而将用户的所有聚类作为corpus。tf-idf会输出对于一个文档的关键词排名,所以只要检查这个聚类分数最高的前几个单词是否在wordlist中,可以决定推文context是否与sensitive venue有关。
Duration-Based corroboration:
用户可能因为地点的敏感性不会在推文中发关键词,所以还用了停留时间作为依据。如果在一个聚类中,相当一段时间内用户发了多条推文,说明用户在该地点花了一段时间,就有可能访问了敏感地点。 但这种判断不confidence。
4. Implementation Details
这套LPAuditor工具全用Python实现,用到的数据放在Mongo db中,这一部分讲的是作者具体都用到什么工具和包,这些工具对社交分析都挺有用的,感兴趣的话可以阅读原论文。