论文:NDSS 2018的best paper award:Knock Knock, Who’s There? Membership Inference on Aggregate Location Data
Knock Knock, Who’s There? Membership Inference on Aggregate Location Data
在涉及数据公开的时候,为了保护用户的隐私,机构通常会公开统计数据,隐去可以识别个体的信息,在公开数据的时候,还要注意不能让人从统计数据中推断出个体的信息。
现在有越来越多的应用,为了提供某些功能需要收集用户的位置序列,并发布聚集的位置信息,例如收集车辆的位置序列来显示一张动态的交通情况地图,估算某条路线的拥堵情况;或者聚集显示某个餐厅的人数,来估算等待时间。因为位置信息、特别是时间序列的位置很敏感,可以从中得到许多用户的个人隐私,所以这种位置的统计数据更要注意不能泄露个体信息。https://arxiv.org/abs/1703.00366这篇文章表明如果有目标用户移动轨迹的一些先验知识,就可以从聚集的数据中挖掘得到更多信息,甚至可以定位该用户; 有时用户的轨迹可以直接从聚集数据中推断,而不需要任何先验的知识。
要从统计数据中推断个体,首先就必须要能推断出某个目标个体的数据是不是该聚集的一部分,这个叫做membership inference. 基于membership inference,membership inference attack最开始是在Membership Inference Attacks Against Machine Learning Models
这篇论文中提出来的一种新的攻击方式,在MIA这篇论文中关注的是机器学习模型的隐私泄露问题,就是推断目标是否出现在某个模型的训练集中。 Membership inference 的方法也可以用在数据提供者要发布统计数据的时候,评估发布的危险性。
作者将membership inference作为一个分类问题,即对一个target user,预测它是否是某个聚集数据的成员。在两个数据集上测试,结果预测的AUC非常高,在有先验知识的情况下,甚至在每一个聚集都包含9500个用户的时候AUC还能达到 1.0。 他们也测试了影响预测正确率的一些因素,例如,每组用户人数、timeframe、数据的颗粒度、稀疏程度。他们用基于差分隐私的方法来研究如何对抗成员推断攻击,发现这种对抗总体都是比较有效的,但是会以牺牲功能为代价,而且当攻击者使用噪声数据来训练的时候,这种保护的效果就不那么好了。
本文的贡献:
- 提出一种聚集位置序列数据的成员推断方法
- 用该方法去量化raw aggregate的隐私泄露问题
- 阐述了这种方法可以如何用来研究defense mechanism的有效性
问题定义
假设一个应用收集U 个用户的数据,发布在一系列的时间区间内,处于某些感兴趣区域(ROI)的用户人数。一个攻击者使用发布的数据,以及可能的一些先验知识,来推断一个个体是否属于某一个聚集的数据。即,我们知道十点-十点十分,在中央公园的用户有100个人,要推断目标个体是不是这100个人中的一个。
记号:
所有用户的集合
所有感兴趣区域的集合:
聚集位置信息被收集的时间间隔:
一个用户的位置时间序列可以被表示为一个0,1的|S| x |T| 的矩阵,其中在$s_{i}$ $t_{j}$ 为1表示该用户在时间区间$t_{j}$ 时正在位置$s_{i}$.
所有用户的位置时间序列就可以被表示为一个|U|x |S|x|T| 的三维张量 L。 用矩阵Ax来表示用户集合X的聚集,其中Ax[s] [t] 表示在t区间内有多少个用户在位置s。
攻击者对目标用户的先验知识标记为 P, 这个先验知识是他在某一段观察时间To ∈ T中观察得到的,先验知识可以用来推断, 要推断的聚集数据在时间Ti ∈ T时发布。
作者把Membership inference任务表达为一个游戏,参数是用户集合U,每个聚集数据包括的成员个数m,以及发布多少个时间区间的数据 Ti
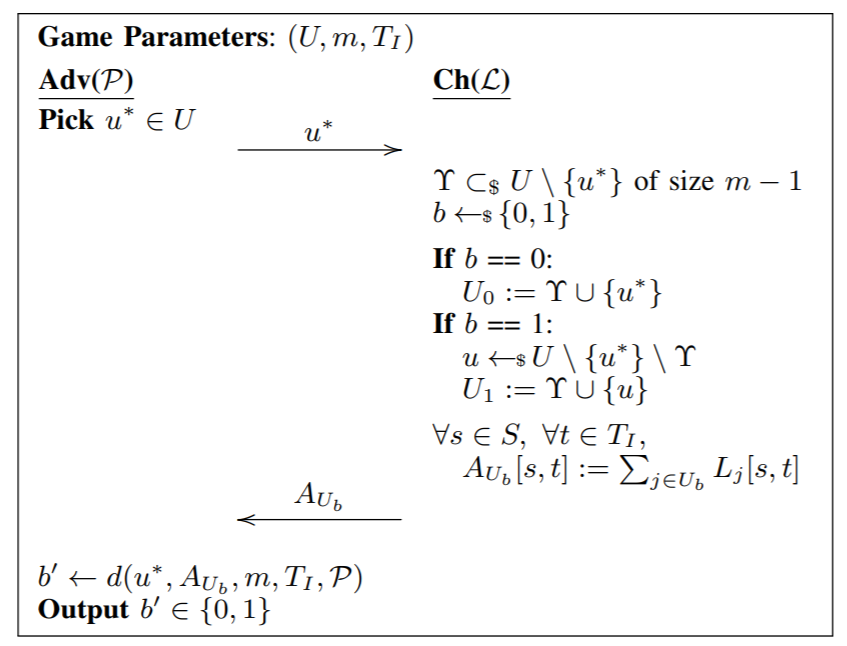
如图,adv先随便取一个目标用户u,然后Ch随机取一个不包含u 的U的子集Y,大小为m-1. 然后随机一个bit b,b就表示了u是不是在聚集中,如果b=1,那就把u和Y中所有成员聚集,得到AUb。如果b=0,就随机取另外一个不在Y中的用户取代u。 把聚集的矩阵Aub返回给Adv。这时,Adv要根据Aub、先验知识P、u、m、Ti来猜测b‘, 目标是让b’ = b。这个猜测b‘的过程 可以看作一个函数d。目标是在多次推断中猜对的概率要大于1/2(瞎猜),越高越好。
Methodology
研究:1. 如何在To内构建先验知识P; 2. 如何构建函数d,或者如何初始化函数d。
1. 构建先验知识P
两种方法:
-
subset of locations:攻击者知道一个包含u*的用户子集在Ti 时间区间中的真实位置。即:
比如说某些可以取得一些用户真实位置数据的攻击者,如app开发者、通信服务提供商等。
-
participation in past groups: 攻击者知道在过去的时间To内,用户u是否包含在某些aggregated group内。即,对于若干个U的自己Wi,知道他们在To的聚集矩阵Awi,以及u是否在这些集合中
这些集合有两种可能:
- 和Ti 公布的聚集是重合的
- 和Ti 公布的聚集可能不重合
1适用于从时间To到Ti,用户和他附近的用户位置都比较固定,例如是在同一个街区的数据。2是攻击者只知道u*在过去一段时间是否属于某些group,但这些group是不太稳定的,所以和Ti收集到的并不一样,例如用户在某个时间点搬家了。
2. Distinguishing function
这里distinguishing function就是一个以m、Ti、u*、P 和Aub为输入的二分类器,用监督学习的方式来训练。
3. 量化隐私泄露
作者用distinguishing function的性能来衡量隐私泄露的情况,即,函数d性能越好,说明隐私泄露得越多。 引入了一个privacy loss metric, 这个metric 基于AUC。
adv做出一系列对b的猜测,然后通过b 和 b’来计算AUC, 其中b=0是positive, b=1是negative,以此计算TP\TN\FP\FN。得到ROC曲线和AUC。
实验
1. 数据集
- TFL transport for london: 伦敦的公共交通, 2010三月。包含每一张Oyster Card的touch in、touch out time、station id的序列。把一张卡视为一个用户,station作为ROI, touch in touch out都算作用户处于该地点。时间粒度是1小时。
- San Francisco Cab network: 三藩的出租车数据; 2008年5月-6月; 包含car id、经度维度、时间戳。 把城市分成10x10的网格,每一个网格是一个ROI,时间区间是1小时,每个id视作一个用户。
TFL 比SFC更predictable,因为日常的出行轨迹有一些频繁模式, 但是比SFC更稀疏。因为SFC中每辆车报告位置比TFL中用户刷卡频繁得多。
把两个数据集中的用户,按他们出现的ROI个数从高到低排序,分为三个等级,从每个等级中采样50个用户,得到150个用户作为攻击的目标。
2. 实验设置
对每一个攻击目标u*, adv要先在从先验知识P中产生的数据上训练,然后在预测阶段的时候给出分类预测。一次实验可以分成3个阶段:
- Aggregate: 在这个阶段,构建数据集D。 重复以下步骤:
- 随机选取m个包括u*的用户,在时间区间Ti内进行聚集,得到对应的矩阵A作为D的一个样本,并且标注为in。
- 随机选取m个不包括u*的用户,标注为out,做同样的事。
重复上面两个步骤就是让数据集正负样本平衡。
- Feature Extraction:对于D的每一个数据样本A,注意A是一个矩阵,每一行就是在一个ROI的聚集情况,对每一行进行一些统计指标的计算,例如每一行的平均值(意思就是某个地方,在时间Ti区间内,平均每个间隔有多少用户在),标准差、方差、最大最小值等等。这些统计指标会作为classifier的输入。
- Classification: 把数据集D分成训练集和预测集,在训练集上训练之后,在预测集上进行distinguish ability game。 实验中采用了scikit-learn的几种分类器:logistic、knn、random forests、MLP
3. 在Raw Aggregate数据集上评估membership inference的能力(raw aggregate就是原始聚集数据,没有采用差分隐私等方法)
对不同的先验知识P,来进行评估。记得先验知识被分为subset of location 和participation in past groups两大类。
-
subset of location:
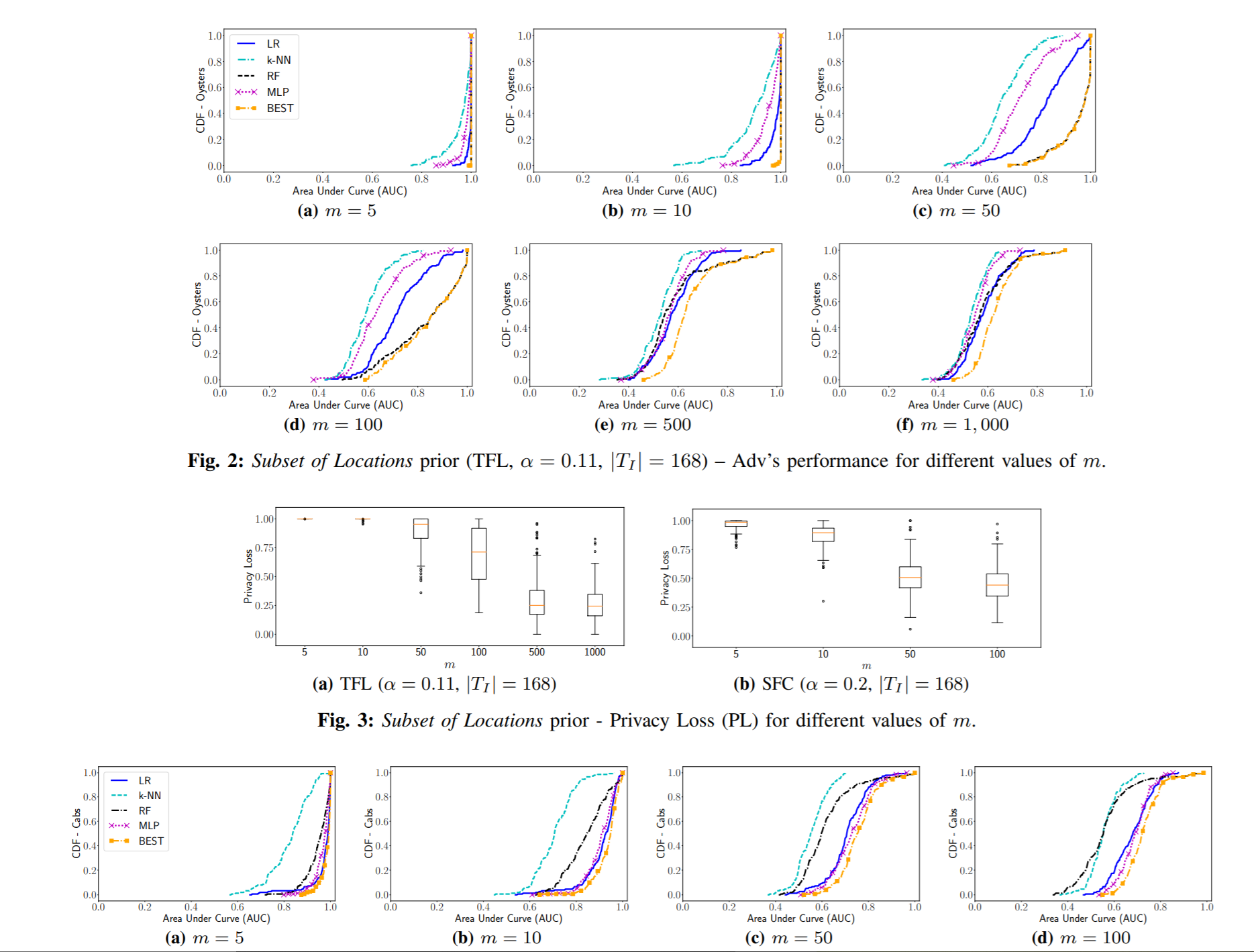
攻击者知道在Ti时间内,包括目标用户在内的一小部分用户的真实位置。那么产生数据集的时候就用这个先验知识, 假设Ti知道的这部分是U1: 1. 从U1产生训练数据集;2. 从U-U1 ∪ {u*} 产生测试集。对不同的每组用户个数m测试AOC:
结果:
fig2是在TFC的结果; fig4是在SFC的结果; fig3是privacy loss与m的关系。自然地,m越小,就越容易泄露隐私,当m与先验知识的大小差不多的时候,就难以推断出membership了。在fig3中,TFL的privacy loss 比SFC高(m<100), 说明在越稀疏的数据集上越容易泄露隐私。
- participation in past groups:
-
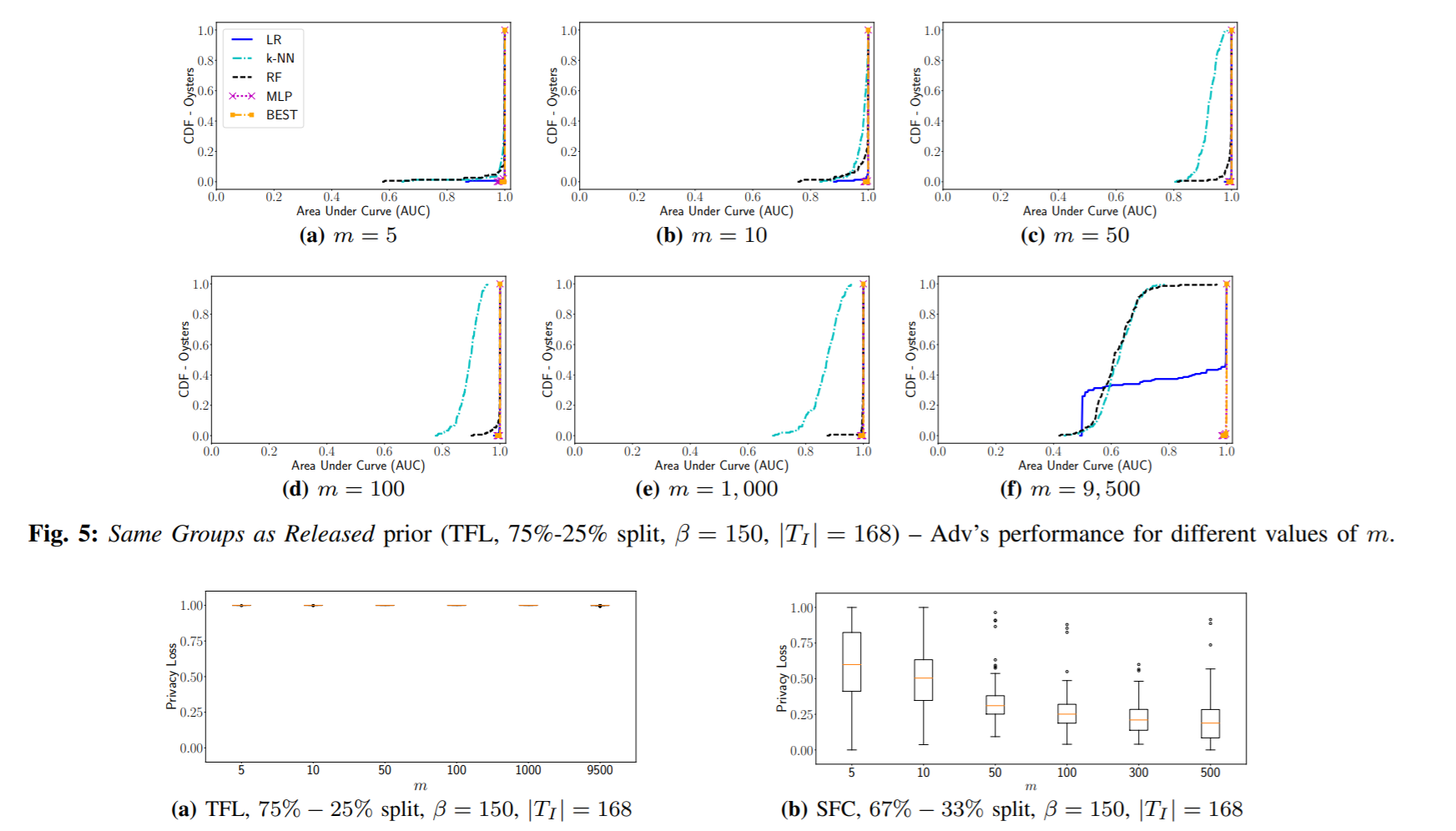
same groups as released: 攻击者知道u在过去的To中,是否参与了某些groups的聚集,而且这些groups和放出的预测集是同一些group。所以数据集D就是先随机采样150个一半包含u,一半不包含u*的用户集,训练集是这些用户集在To时间内的聚集,测试集是它们在Ti时间内的聚集,也就是把D按时间划分。
结果:当m=9500的时候,MLP仍然可以得到0.99的AUC,说明当mobility patterns随时间很稳定的时候,如果攻击者有prior knowledge就可以成功地在未来推断u*,即便用户集非常大。但是在SFC数据集上效果就明显差了,当m很小的时候,AUC只有大概0.6-0.7,比起TFL的0.99-1.0差了很多,当m增加的时候,传统模型就和random guess差不多,MLP也掉到0.57. TFL是人们公交打卡的数据,这种会非常规律,而SFC是出租车数据,这种则比较随机,所以past knowledge就难以推断未来。这说明了regularity和membership inference的关系。
-
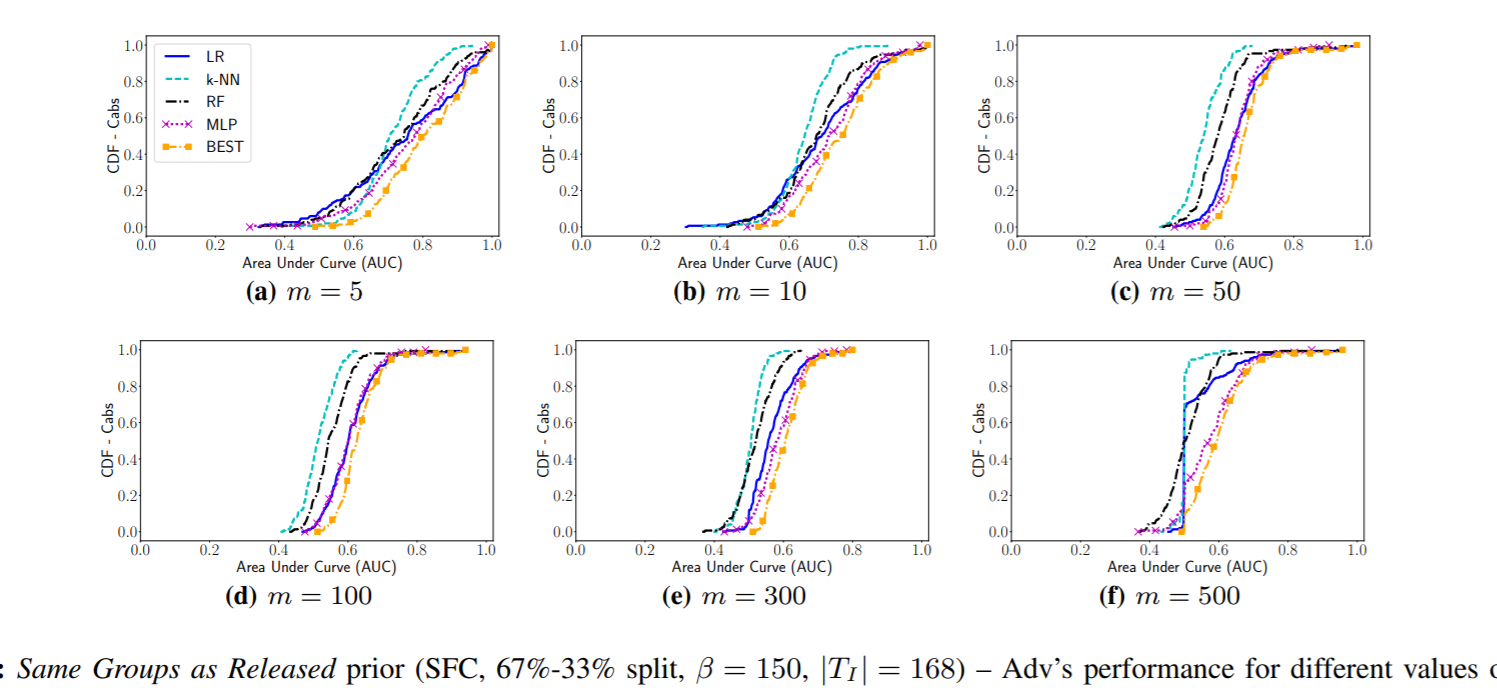
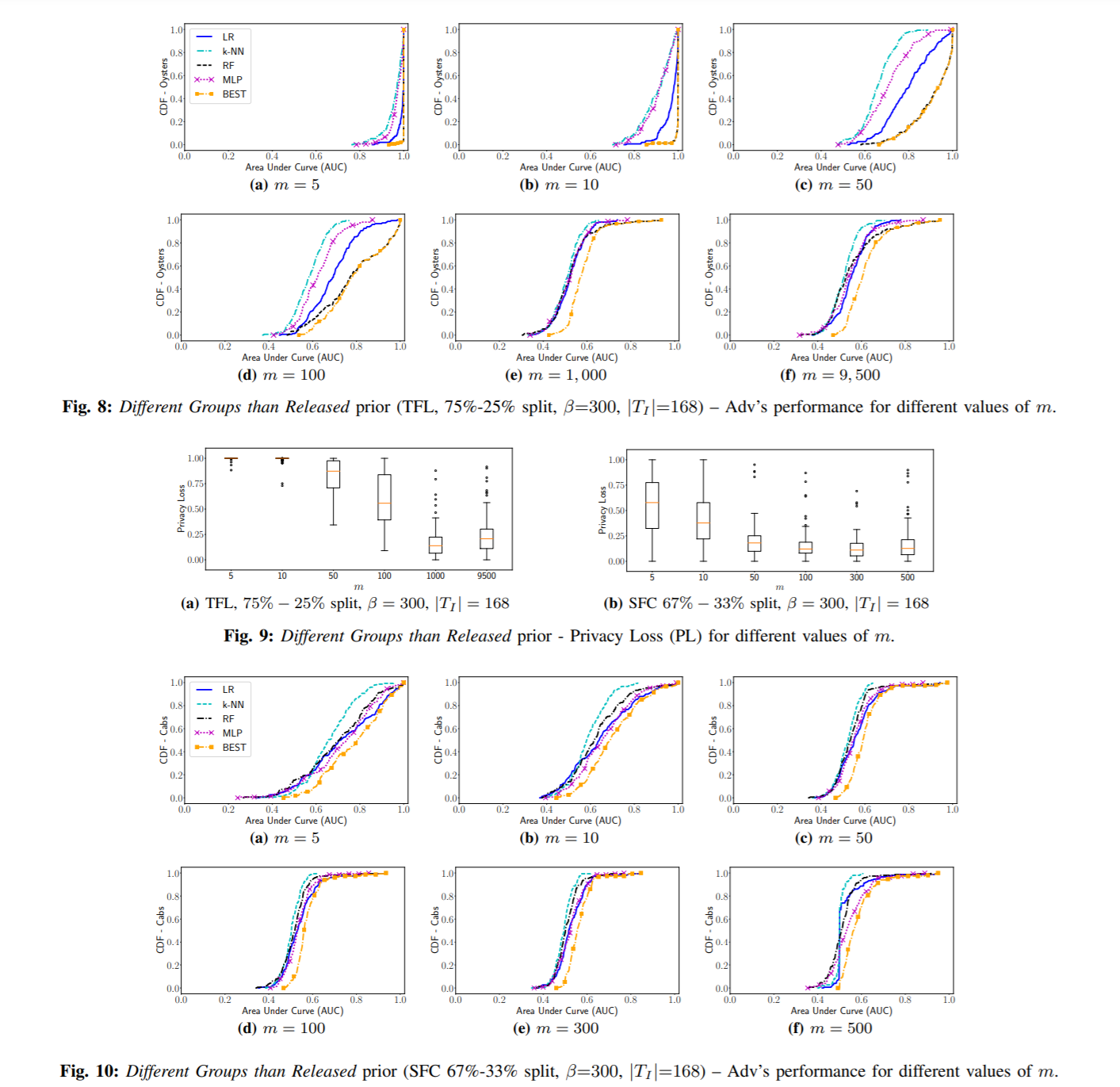
different groups than released: 先随机采样400个用户集,一半包含u*一半不包含,然后随机分成300个给训练集,100个给测试集,训练集在To时间内聚集,测试集在Ti时间内聚集。
结果:
TFL在m很小的时候,仍然可以得到很好的结果;当m增加到100-1000,所有分类器的性能都大幅下降,传统模型和random guess差不多,但是当m=9500的时候,因为训练集、测试集用到的user group有很多交集,所以效果就比较像same groups as released的情况,会好一点点。总的来说privacy loss 比之前小了很多。SFC也有相同的模式,但SFC数据更没规律,所以结果比TFL差。
-
-
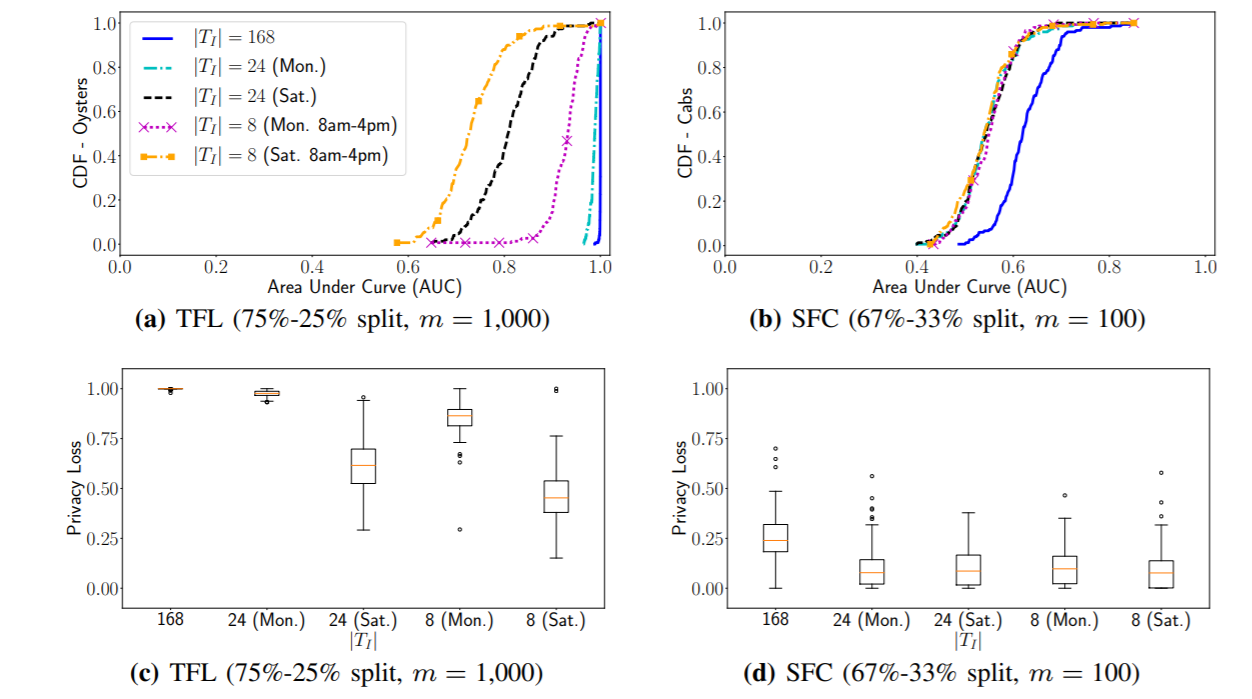
考虑Ti时长的影响:
设置Ti 为 8小时、24小时、168小时,在TFL\SFC上分别实验,设置为prior knowledge=2.1,m=1000和m=100,用各自最好的分类器,结果:
在TFL数据集上,Ti缩短AUC下降,因为时长不够模型发掘规律;而且weekday 和weekends也有显著的差别,在星期1 Ti=8时,效果明显比周六好,因为周一人们公交打卡是非常有规律的。在SFC上,则除了Ti=168以外,其他都没有明显区别,而且都接近0.5.
Take-away:当攻击者知道包括目标用户在内的用户群体真实位置、或者知道过去一段时间目标用户的成员情况时,membership inference是很容易实现的。它的效果和数据集本身的特征(稀疏性、规律性)有关,和聚集的用户数m有关,和timeframe以及预测的时间在周末/工作日 有关。
evaluating DP defenses
1. 差分隐私介绍
差分隐私用来保护数据集中的差别导致的隐私泄露。定义相邻数据集D1, D2,他们有且仅有一个元素不一样:
对于一个随机化算法M(也就是对于同一个输入不一定会产生同一个输出,产生何种输出符合某种分布), 如果在D1和D2数据集中产生结果O的概率分布大致相同,就说这个算法达到了差分隐私的效果。形式化表达:
为了衡量一条数据的差别对某个函数的输出有多大的影响, 定义 sensitivity的概念:
常用的达到差分隐私的方法是在数据集或者输出上加随机噪声,常用的是拉普拉斯噪声。将M定义为:
随机算法M达到ε-差分隐私,当
还有一种较弱的方法,就是在时序聚合的数值加Lap(1/ε)的噪声,但只能保护单个location visit,所以在本文只作为一种baseline方法。
高斯噪声: 比Laplacian弱的是在输出加高斯分布的噪声。
FPA: 专门针对时序聚集数据的方法是使用离散傅里叶变换的FPA,一个时间序列用离散傅里叶变换进行压缩,然后保留前k个系数,用拉普拉斯噪声干扰,最后用0 padding到原来的长度,逆变换。
EFPAG: enhanced fourier perturbation algorithm with gaussian noise: 按某种概率选择FPA中的k,使得原序列和经过干扰之后的序列root sum squared error最小,并且用高斯噪声代替拉普拉斯
加入噪声会使数据变得不准确,当数据量小的时候,噪声的影响相对较大,作者也提到证明了数据量较小的时候,使用以上方法数据的可用性有很明显的下降。所以接下来的实验都是在m较大的情况下完成的。
2. 实验
为了评估差分隐私方法对抗membership inference 的有效性,实验假设了一种最坏的情况,就是攻击者拥有非常多的先验知识,即同时知道prior knowledge 1 和 2.1(准确位置和u*以往的membership)。有这些prior knowledge,分类器的AUC基本上是1.
测试数据集现在聚集的时候用以上的差分隐私方法进行干扰。训练数据集则有两种产生策略:
- row aggregation: 即分类器在没有进行干扰的聚集数据上训练
- 采用了和测试数据集一样的干扰方法的训练数据, 这个模仿的是一种比较active的攻击者,知道使用了什么样的保护策略,并在模仿这种保护策略的数据上进行训练
metrics: 引入privacy gain的概念来衡量对抗方法的有效性。

用row aggregate 和 加入噪声之后的聚集之间的mean relative error来衡量utility loss。
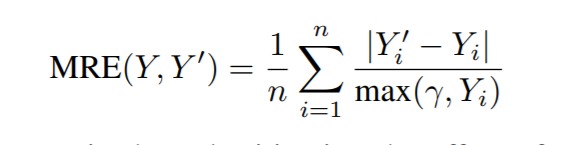
效果:
当保护比较严格(ε很小的时候),攻击者是否用了干扰的数据训练对于PG没有很明显的不同,但是当ε较大的时候,可以看到即使在SFC数据集上,PG也下降了很多。
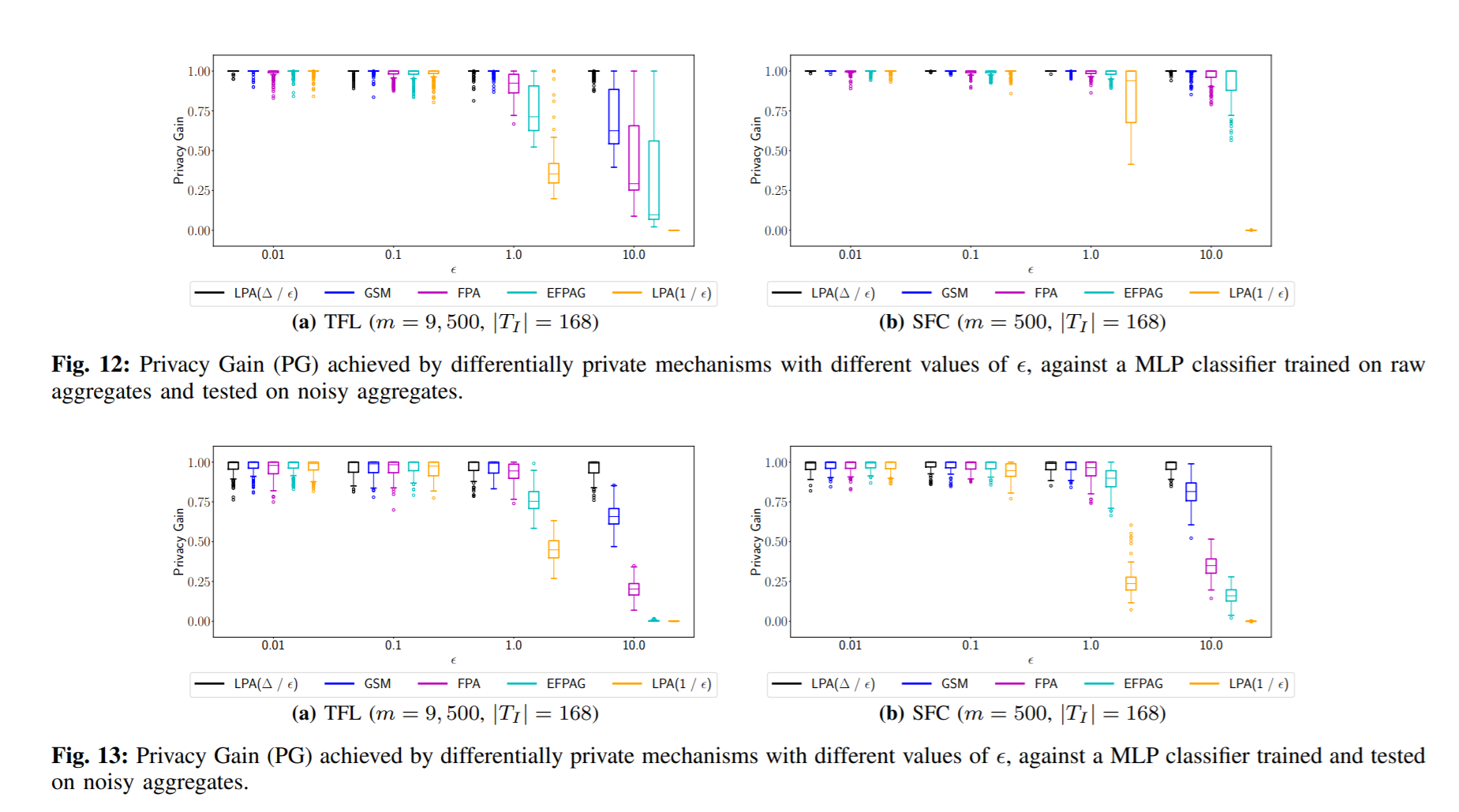
用拉普拉斯、高斯噪声干扰utility损失很多,而FPA等方法对utility的损害就比较小,但是以privacy loss 为代价,utility和privacy loss之间是trade off 的关系。
最后我比较怀疑的是文章中这种membership inference的方法在现实中是不是真的能够实现……就如果攻击者可以知道包括target user和其他一些用户的位置的话,ta就可以用这些数据来以文中的方法产生训练数据,但既然已经知道target user的真实位置,怎么会还有必要去做membership inference呢? 而如果攻击者可以知道target user过去是否属于某些group,那ta又是怎么知道这种信息的,是不是要比较了解该app聚集用户信息的方式,或者本来就已经知道该用户的活动范围了?然后是否有可能像文中一样,知道的这些信息中正负样本是1:1平衡的呢?样本不平衡的话分类器效果就没那么好了。不知道我的理解是不是正确的。