内容提要:
- 图卷积原理和基础版
- graphSAGE
- graph attention network
回到node embedding问题,之前的DeepWalk以及node2vec等等,用的都是“shallow embedding”,他们的encoder函数都是相当于一个lookup table。
这样的做法有什么局限性?
- 要学习的参数非常多, 整个表都是要学习的,n个节点,d维表示,那就是nd个参数,而n往往是非常大的。
- inherently transductive: 它不能产生那些不在training过程中的节点的embedding,就是如果有一个新的网络/新的节点,同样的参数不能在新网络上使用,必须重新训练。
- 没有考虑节点本身的特征,只是考虑了网络结构。
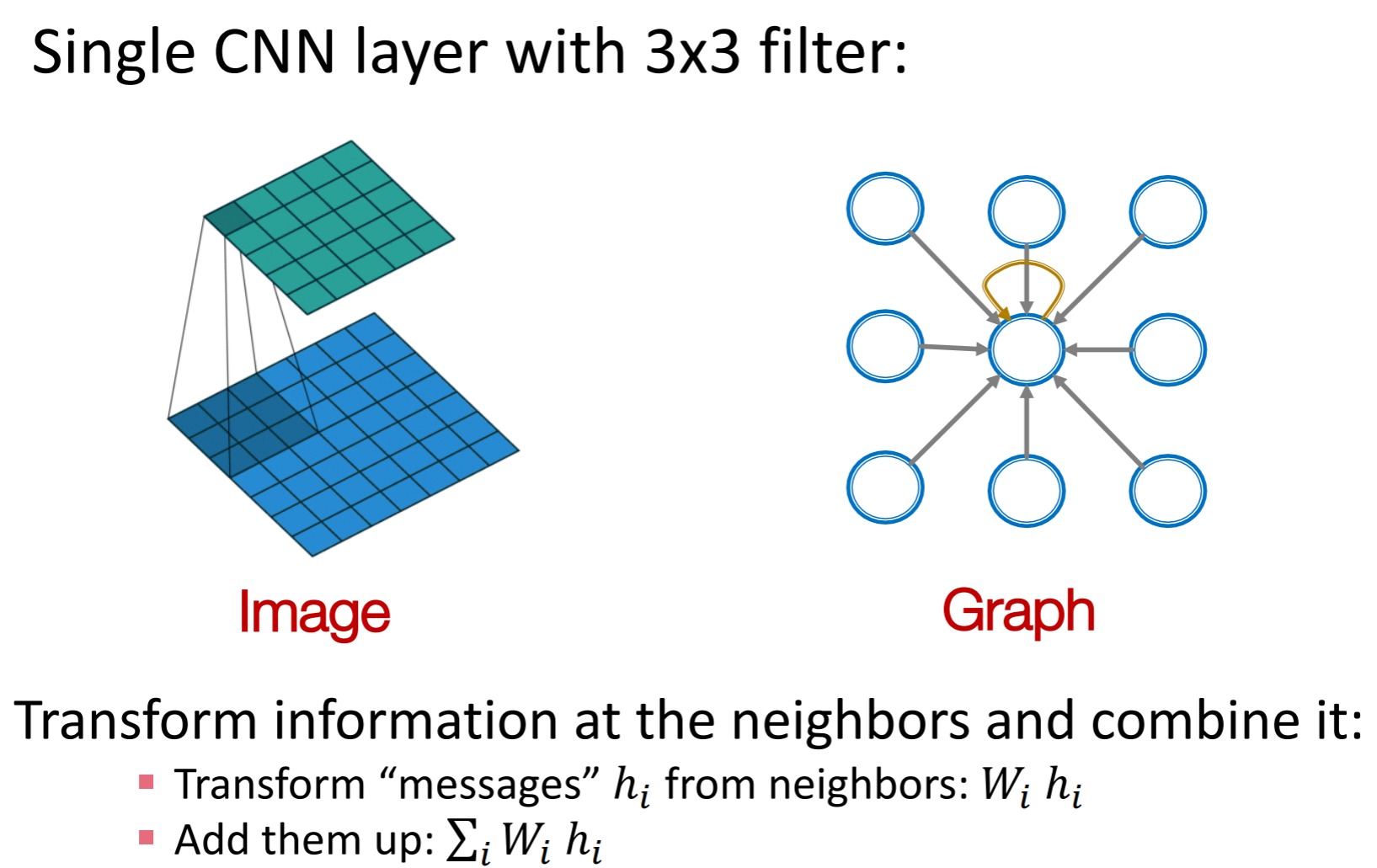
Graph Convolutional Networks
在网络上的“卷积”,可以看成是中心节点从它的邻居聚集 信息
一个直接的想法: 用adjacency matrix直接作为dnn的输入
这个方法不行:
- 首先parameter会非常非常多, 只第一层输入层的参数就有n* feature dimension 那么多, 这个参数会远远多于训练数据
- 对于大小不同的图无法使用,因为输入必须是固定的大小,但网络的结构是经常变化的
- not invariant to node ordering, 网络节点标号不同的顺序,得到的结果应该是一样的。
Deep learning for graphs
G, V, A, X是node feature matrix
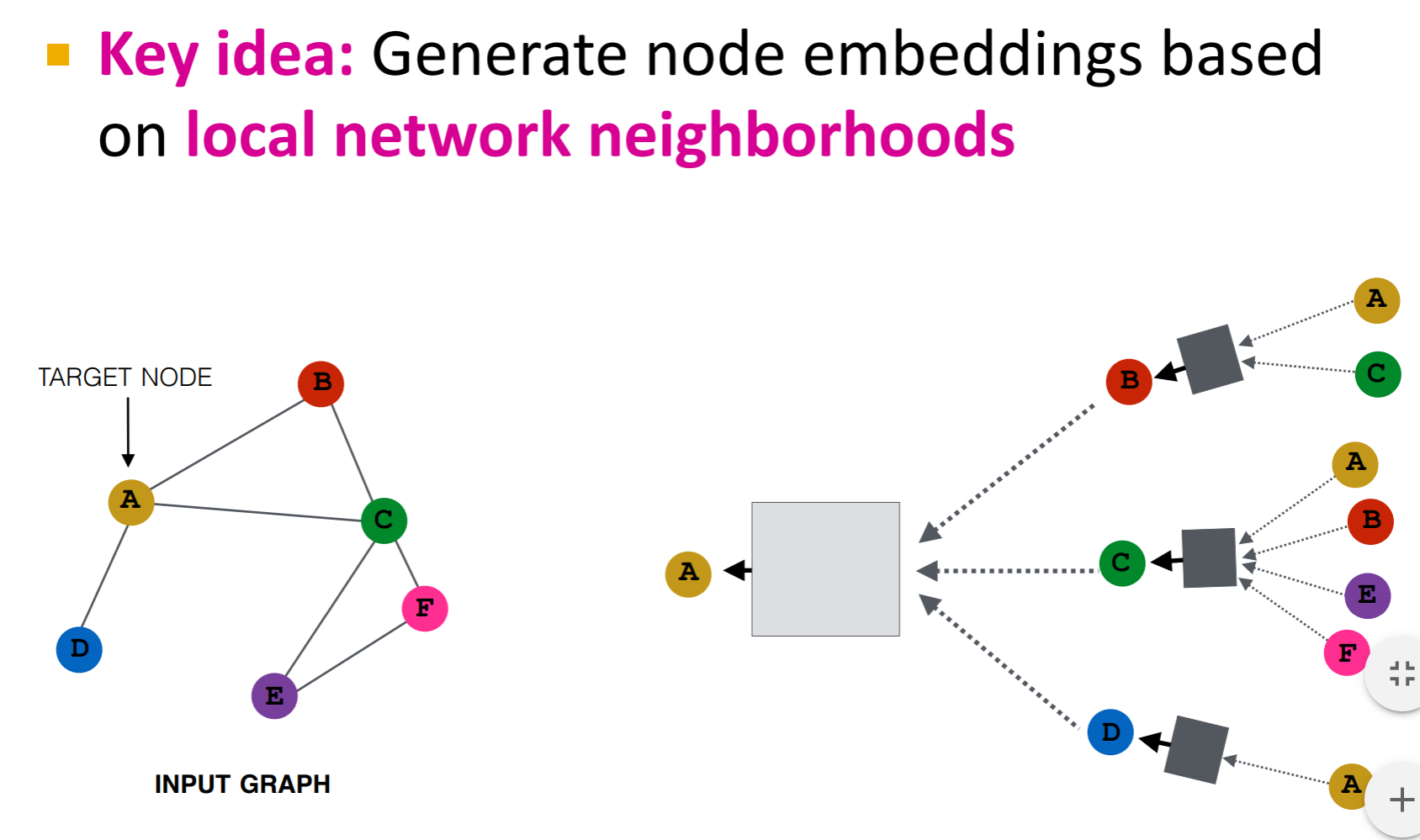
这个aggregate function,就是图中的方块,应该是节点顺序不变性的, 比如说求最大值、求平均值等等, 经验表明,summation的效果比较好。
上图右边就是一个 两层的neural network, 一般来说, 在图上的dnn层数不会很深,因为社交网络的直径在6左右!所以一般3、4层就可以了。
layer -0 的输入就是节点的特征向量x,然后每个节点会聚集邻居的特征向量x,直到最顶层, 最终得到节点的embedding
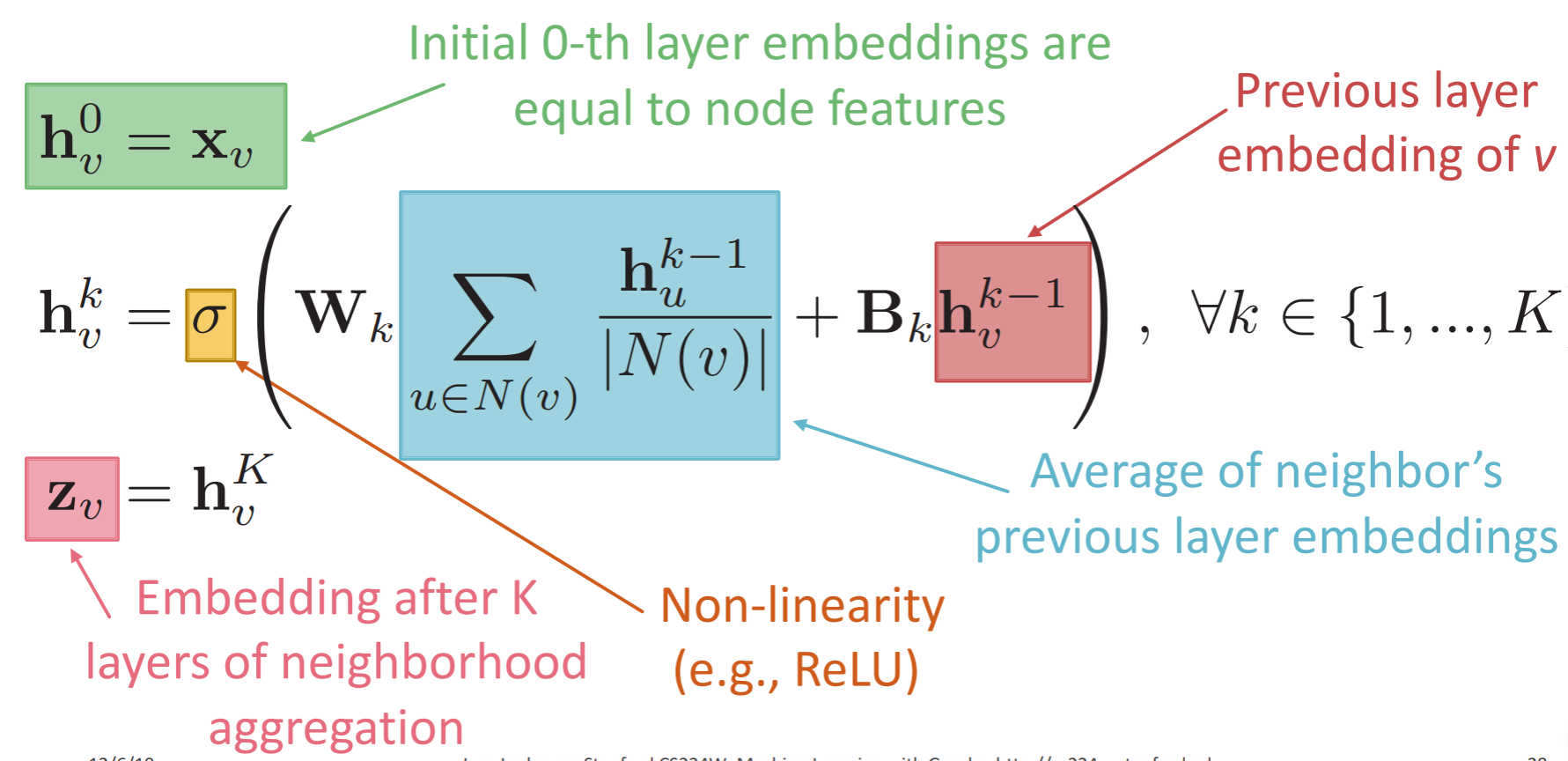
要学习的参数是Wk和Bk (两个都是矩阵,和特征的维数应该是一样的。
如何训练?
可以是unsupervised training, 用random walks、graph factorizing来表示节点的similarity, 然后相似的节点应该有相近的embedding。
也可以直接对具体的任务做supervised training、semi-supervised training。
例如:
- node classification
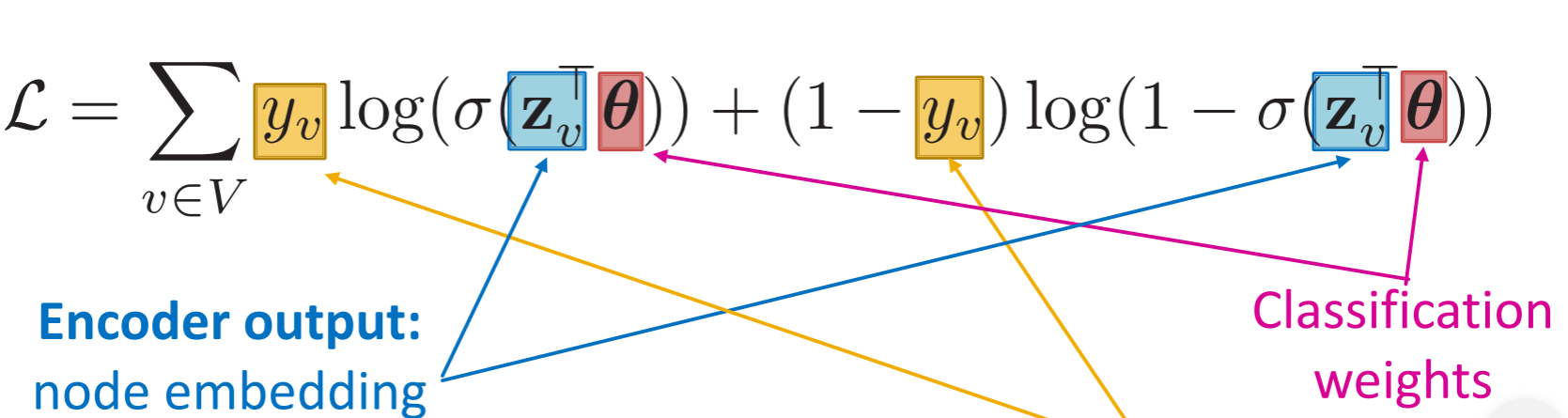
因为W和B只是不同的层是不一样的, 而对每一个节点是一样的, 所以如果网络加进来了新的节点, 可以在原来那一部分训练好模型之后, 直接apply到新的节点上。
GraphSAGE
和上面相比, GraphSAGE的两个不同,一个在于可以用不同的Aggregation函数,另一个在于不是直接把邻居和本节点融合(+),而是向量拼接。
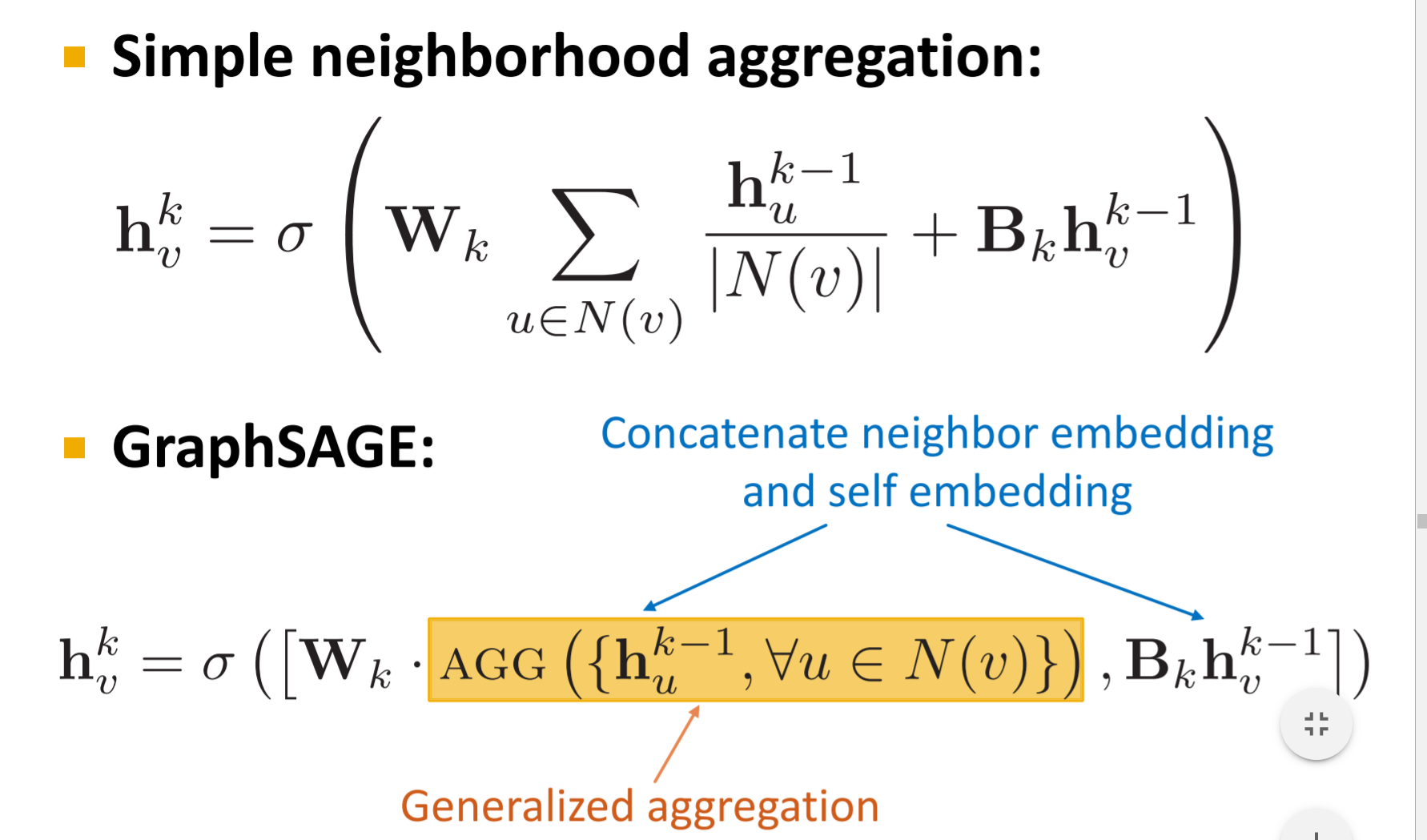
对不同的问题,可以采用不同的聚集函数:
- mean
- pool,可以取最小或者最大值
- LSTM: 因为embedding是需要顺序不变性的,但LSTM输入是顺序的, 所以可以用随机顺序输入训练。
其中, mean aggregation可以用矩阵相乘的方式非常快地实现:
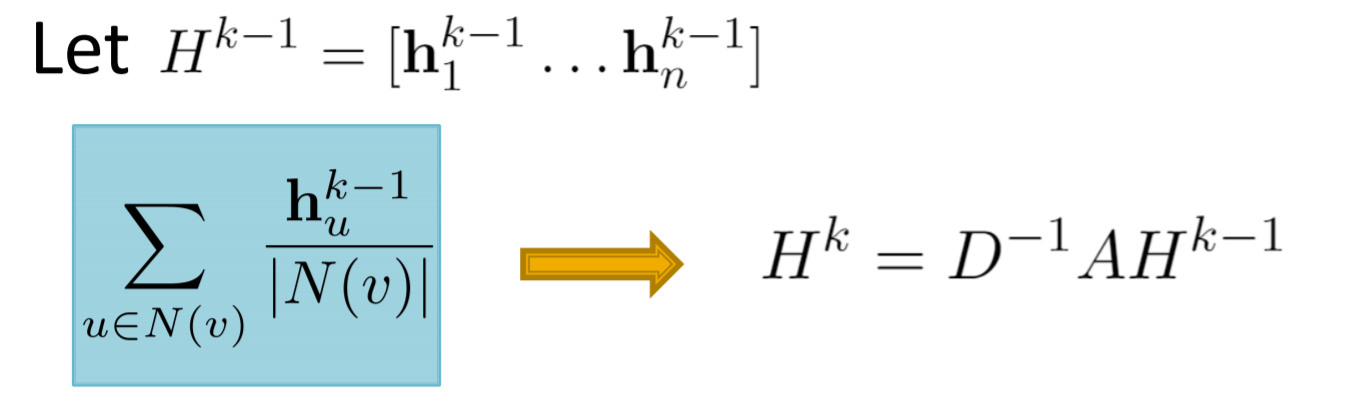
| D是度数矩阵, 相当于除以 | N(v) |
如果是有权重的图, 一种方式是在mean aggregation中, 用加权平均。
embedding和GNN方面最新的论文:

Graph attention network
| 上面的方法中,每一个邻居对某个节点的“贡献”是一样的,可以看成它们都有相同的权重 α=1/ | N(v) | . |
attention strategy 1:
用某种方式,来计算出节点v的邻居u的attention coefficient:
计算出所有邻居的attention coefficient后, 节点的权重 α可以用softmax归一:
这样,每一层在计算embedding的时候,聚集函数,例如mean,就是每一个邻居上一层embedding的加权平均,权重=α.
如何选择函数 a?
- 有看到一些具体的任务,a就是直接两个向量进行点积(类似于余弦相似度,和原节点越相似,那么这个邻居节点就越重要),这个应该可以根据任务的不同,自己定义一些重要性的函数,例如相似度、距离等等。
- a可以是一个参数可以通过训练调节的简单神经网络。
- 如果图本来就有权重,可以直接将边权作为attention coefficient,也可以在a中加入这个因素。